Examples of Data-based Heritage Interpretation
This section demonstrates various functions made possible by data-based heritage interpretation through the utilization of the ontology presented in the previous section. The examples presented here are grouped by five ideals of interpretation. The examples will include a description of the nodes, relations and properties as appropriate for each example, screencaps of the Neo4J graph data visualization program into which the data was inputted. Cyphers used to query the example in Neo4J will be provided in the footnotes. The data used for these examples can be downloaded via the Excel files linked below. Data is organized by node label or relation label into spreadsheet tabs, and each tab includes Neo4J Cypher queries which can be inputted (nodes first, then relations) into Neo4J by hand to generate the nodes and relations used in the following examples.
Contents
Improving Accuracy and Clarity
First, measures were put in place to facilitate greater transparency in who is creating and translating the information and what the sources of the information are. Ideally this means that 1) creators and translators feel a greater sense of responsibility for their work (compared to now, when they are nameless and unable to be identified), which will improve the accuracy and quality of the information. By including sources, audiences can see where the information came from and draw their own conclusions on the quality of that source, or, if not source is cited or if a relationship is considered “presumed” and not certain, they can be made aware of the fact that the information they are receiving may not be accurate.
If, at the time of node editing or relationship creation, a “meta” relationship is created, which shows who did the editing, when it was edited, which attribute of the node was edited, the ID for the source for the information added or changed in the node (underlined and in bold), then such additions and changes of meanings, relationships, and translations in the database can be tracked.
Figure 16 Meta label relationships for transparency[1]

| Domain | Relationship | Range | |
|---|---|---|---|
| Label | user | meta | person |
| Properties | id: lyndsey + others | type: meta_edited, kr: 수정하였다, en: edited, attribute: def_en, ref: RS000001, user: lyndsey, date: 20170522 | en: Sin Suk-ju + others |
Unfortunately, it is not possible to create a “meta” relationship to describe the relationships themselves. Therefore, only one source of information for the relationship can be stored as an attribute of relationship, and each time a relationship is edited, the relationship creator and creation date should be updated to reflect the most recent edit.
The following example shows how, using the veracity attribute, one can query any relationships which are considered presumed. Though not shown here, relationships or attributes missing cited sources can also be compiled in a similar way. In this example, it shows that “Cheongjuhyangyo Confucian Academy was founded during the reign of King Taejo,” but that this relationship is presumed and not known for certain. This example also shows the possibility of querying relationships based on relationship properties.
Figure 17 Use of relationship properties to demonstrate veracity of claims[2]

| Domain | Relationship | Range | |
|---|---|---|---|
| Label | tangibleobject | start | tempobject |
| Properties | en: Cheongjuhyanggyo Confucian Academy + others | date: 20170601, ver: C000027, en: was founded in, type: wasFounded, id: rel11035, user: lyndsey | en: the reign of King Taejo + others |
| Label | concept | ||
| Properties | id: C000027, en: presumed |
The next example shows a case where there is conflicting information – as shown the example in Section IV.1 The data shows that three different dates are listed for the relocation of Song Sang-hyeon’s tomb from Dongnae to Suui-dong in Cheongju. Since the original texts referenced do not include the primary source from which the information was included, the institution which presented the information was listed instead (CHA or the government of Cheongju). As such, users can only make the determination of which institution is more trustworthy. If the original source had been cited, then users could go and check to see which date is correct, and the incorrect relationships could be deleted.
Figure 18 Visualization showing three different dates for the relocation of the Tomb of Song Sang-hyeon[3]

Figure 19 Inconsistencies in dates of events and their source institutions[4]

| Domain | Relationship | Range | |
|---|---|---|---|
| Label | tangibleobject | trans | tempobject |
| Properties | en: Tomb of Song Sang-hyeon + others | date: 20170601, before: 15940000, en: was relocated, type: wasRelocated, from: IS000010, to: IS000012, id: rel11013, user: lyndsey | en: unknown + others |
| Label | tangibleobject | trans | tempobject |
| Properties | en: Tomb of Song Sang-hyeon + others | en: was relocated, type: wasRelocated, ref: RS000008, from: IS000010, to: IS000012, id: rel11015, user: lyndsey | kr: 1595년, en: 1595, id: 15950000 |
| Label | tangibleobject | trans | tempobject |
| Properties | en: Tomb of Song Sang-hyeon + others | en: was relocated, type: wasRelocated, ref: RS000007, from: IS000010, to: IS000012, id: rel11014, user: lyndsey | kr: 1610년, en: 1610, id: 16100000, reign_en: Gwanghaegun 2, reign_kr: 광해군 2 |
| Relationship Property Above | before | from | to | ref | ref |
| Label | tempobject | spatialobject | spatialobject | secondaryref | secondaryref |
| Properties | id: 15940000, en: 1594 | id: IS000010, en: Dongnaeseong Fortress | id: IS000012, en: Suui-dong | id: RS000008, source: II000005 | id: RS000007, source: II000008 |
| Label | institution | institution |
| Properties | id: II000008, en: the government of Cheongju | source: II000005, en: Cultural Heritage Administration |
One of the common messages by heritage interpretation scholars and the CHA is that the message must be understandable to the audience. However, not all audiences have the same background knowledge or learning styles. This ontology allows for the inclusion of explanations for concepts, historical figures, and events as needed (as can be tailored by the audience themselves; see the following section). The ontology also includes, of course, information on dates of creation, transformation, and destruction of heritages, births and deaths, events, etc., which can be conveyed in traditional narrative form via an automatically generated text, or alternatively, in the form of a timeline. This is shown in the following section. Though an example is not presented here, the ontology also includes the ability to convey the layout of buildings and relationships between parts of structures so that in the future this information could be conveyed via automatically generated diagrams (which could be presented in various languages with various labels depending on the settings).
Making Interpretation Personalized
This ontology allows for extensive tailoring of the content which is displayed and personalization of how it is displayed. First, because the ontology allows for nodes and relationships to have attributes in in Korean, English, and Chinese characters, users can choose the language in which to display the information or even have a combination of languages (shown below). This extends to choosing to display information on dates (i.e. whether to show solar or lunar calendar dates, whether to include or omit information on reign years like “Taejo 1”), and measurement units (metric versus imperial).
The following example shows how, by utilizing the various properties stored within nodes and relationships, the same information can be conveyed in different languages, including/excluding definition to matching the audience’s needs for understanding, and have said information presented in various forms (text or visualized, for example) so that each audience member has a greater chance of understanding the interpretive information.
Table 24 Domain, relationship, and range for “Cheongjuhyanggo is a Confucian Academy”
| Domain | Relationship | Range | |
|---|---|---|---|
| Label | tangibleobject | type | typalconcept |
| Properties | ch: 淸州鄕校, kr: 청주향교, en: Cheongjuhyanggyo Local Confucian School, id: TC00002 | date: 20170601, kr: ~이다, en: is a, id: rel14176, type: hasType, user: lyndsey | kr:향교, rr: hyanggyo, mr: hyanggyo, ch: 鄕校, def_en: a local, public Confucian school with a shrine for famous Confucian sages |
- Figure 20 The same nodes and relationships visualized in Korean, Chinese characters, and English





- Figure 21 Various ways to generate text for different audience needs using the same data
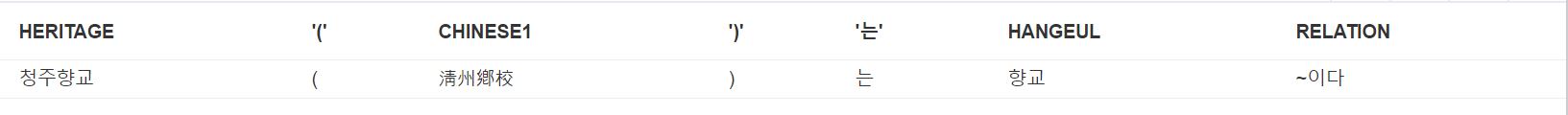





Second, because relationships have labels, users can choose the type of relationships they want to be shown. Maybe someone is interested in history, so they choose to show only the history-related “start,” “trans,” “end,” and “act” labels. Maybe they are only interested in conceptual information and a heritage’s value, and show only “type,” and “value” relations. The ontology also allows for the same tailoring via node labels. Maybe someone is only interested in how this heritage relates to a historical figure, and chooses to show only the relationships between the heritage and the historical figure. This ability to tailor the content which is displayed will be useful for research as well, as academics can choose the kind of relationships between nodes that they which to analyze.
In the following example, we see the network of relationships and nodes connected to the historical figure Sin Suk-ju. The breakdown of the labels of these relationships and nodes are as follows:
Figure 22 All interpretive information on Sin Suk-ju in English[7]

| Domain | Relationship | Range | |
|---|---|---|---|
| Label (Quantity) | person | name (3), start (1), end (1), rel (1), type (2), act (2), value (2) | name (3), tempobject (2), group (1), tangible object (2), typal concept (4) |
However, using different queries, we can choose what information is shown. For example, we can exclude information on the various names Sin Suk-ju had:
Figure 23 Interpretive information on Sin Suk-ju excluding his appellations[8]

| Domain | Relationship | Range | |
|---|---|---|---|
| Label (Quantity) | person | start (1), end (1), rel (1), type (2), act (2), value (2) | tempobject (2), group (1), tangible object (2), typal concept (4) |
Or, we could alternatively choose to display only the various names he had:
Figure 24 Interpretive information only on Sin Suk-ju's appellations[9]

| Domain | Relationship | Range | |
|---|---|---|---|
| Label (Quantity) | person | name (3)) | name (3) |
Even though the information shown is different, all the data remains – it is just hidden from the sight of the user. This is helpful in creating tailored interpretive texts so that they feature the kind of relationships the user is most interested in – history, artistic qualities, concepts, historical figures, etc., and would also be useful for research.
Third, because graph databases allow for searching of information via relationships, the user can choose the amount of information to be show; they may only want to see the nodes directly connected to a heritage, or they may want to see the nodes related to the nodes related to the heritage. A graph database model allows the user to expand outward to related concepts, which means people who want short interpretations get short interpretations, and those who want detailed ones, get detailed ones.
In the following example, we can see how this depth of information can be tailored. The first example shows the nodes which are connected to Sucheonam Ritual House, Cheongju by just one relationship (node-relationship-node).
Figure 25 Contextual information on Sucheonam Ritual House, Cheongju, alone[10]

However, there are certain elements of the context of Sucheonam Ritual House, Cheongju which would be useful to learn more about in depth – in particular, value-label relationships, which connect heritages to the other nodes which give them their “value” as a cultural heritage. These “value” relations have been made bold blue in Figure 25. In the case of Sucheonam Ritual House, Cheongju, the main value is that it is related to Bak Hun, Buddhist Monk Seonjeong, and other nearby tangible objects. When these secondary value relationships are also included (i.e. the addition of node-value-node-relationship-node), the context is broadened as such:
Figure 26 Context of Sucheonam Ritual House, Cheongju and nodes with which it has a value-labeled relationship[11]

As Figure 26 shows, we can also have easy access to further information on the specific contextual elements which give a heritage its value. This could be used not only for heritages, but also depicting the significance of historical figures and historical events. While the examples presented above are visualizations, this ability to control the depth and length of information in text form would also be possible.
While the program used for these examples, Neo4J, only facilitates tables (which can mimic automated text) and graph visualization, if other interfaces are developed, the data could be displayed in a variety of ways to meet the learning style and objective of the user. This is especially useful because we cannot know exactly what technology mediums will become popular in the future – these interfaces can be generated when needed as the time comes, while the data can be enriched starting from today.
Conveying Not Just the Heritage, But Its Context, Too
This ontology allows for the inclusion of not just heritages, but related contextual elements, including places, historical figures, events, concepts, institutions, and more. Furthermore, it allows for the inclusion of information about the contextual elements themselves. As shown in the examples above with Sin Suk-ju and Sucheonam Ritual House, the ontology can describe and connect contextual elements to one another, regardless of whether they are a heritage or not. In this way, the focus truly becomes the contextual world of Korean cultural heritages, and allows information on heritages to be organized around these contextual elements, not just around physical heritages.
This means that users can search for heritages via very nuanced facets if desired, which is useful in research and in finding related heritages. For example, if users are visiting a heritage and they find a particularly beautiful design on the heritage (maybe a window frame or a painting or a piece of pottery) interested in a particular design on the heritage, they could search for other nearby heritages which feature that design, and be provided with more information on the design itself, as well as information on the location of other heritages which feature that design.
The following example shows all heritages which have the umbrella type “shrine” (i.e. they may have the type “portrait shrine” but that is a subtype of “shrine” in general) and located in Cheongju, with the heritage in which they are located, what kind of shrine they are, their name, and their address listed.
Figure 27 Tangible objects with super type “shrine” in Cheongju[12]

The next example shows a search for heritages which end in ‘-gak 각,’ which is usually translated as pavilion, with their dimensions in kan[13] also listed. They are then organized by the heritage of which they are a part, with their type and address included.
Figure 28 Tangible objects with ending ‘-gak’ and their dimensions in kan[14]

This example is of interest because the on-site interpretive text of the Commemorative Pavilions of Yeosan Song Clan, Cheongju[15] makes the claim that one of the pavilions is unique because it is ‘ilmunsamnyeo’ – literally ‘one gate, three commemorations.’ This means that three commemorations are included together in one structure, rather than each having their own structure. This pavilions is three kan across, and one kan deep – while most are one-by-one. By being able to look at the dimensions, we can indeed see that that pavilion stands out as being different from the rest. If the database was enriched with the dimensions of all “-gak” pavilions (not just of those of the few included for the sample), we could indeed see in numbers just how uncommon this structure actually is. Though not shown in this example, one could also potentially search for commemorative structures which have more than one commemoration in them (as these are included in the ontology as ‘parts’ or the structure. In other words, by providing information on a single heritage in the context of other similar heritages, claims of being “unique,” or the “oldest” can really be put to the test. Furthermore, if too many of a particular type of heritage are described as “refined” or “exquisite,” we can begin to acknowledge that these words are actually quite meaningless in conveying the value of the heritage and find more useful ways to describe a heritage’s unique artistic qualities.
Facilitating Further Engagement
The following examples demonstrate how this ontology can allow for further engagement with Korean cultural heritage interpretive information.
First and foremost, the very nature of the database means that even the general public could potentially contribute to the enrichment of the data, which is one source of potential engagement not currently available. A main target of this kind of engagement are high school and university students who could use the database to search for or analyze existing information and draw new conclusions, or input their own data for their own research purposes. In addition, because of the options for personalization as mentioned above, the public, by tailoring their interpretive resource themselves, are empowered to become more involved with the information itself and are forced to reflect on the information they are receiving, which is not currently possible.
In addition to this, there are also particular features of this ontology which directly encourage users to be creative with the interpretive information and seek out further opportunities for engagement – including academic sources, events, or other educational opportunities. For example, one can search for photos (or other mediums such as video, diagrams, etc.) based on a particular concept, time period, etc., and also recall specifically what it depicts and the name of the heritage to which it is related. For example, someone could search for photographs of all wooden structures built in the 17th century and put them in order of date of construction – and literally be able to see the changes in architectural style over time via the photos. Or, if someone does not understand a particular concept (such as a part of a statue or architectural feature), they can pull up all photos which depict that concept in an attempt to better understand it – great for visual learners. This could also be particularly useful for content creators who need to search for photographic references for their work, or academics or educators looking to research or explain differences in features over time or across regions in a visual way.
Figure 29 Visualization of all photos and the tangible objects they depict[16]

| Domain | Relationship | Range | |
|---|---|---|---|
| Label | primaryres | engage | tangibleobject |
| Properties | type: CT000142 + others | type: Depicts + others | + others |
| Label | typalconcept |
| Properties | id: CT000142, en: photo |
Figure 30 List of heritages, their parts which have photos depicting them, and the photo's URL[17]

| Domain | Relationship | Range | |
|---|---|---|---|
| Label | tangibleobject | part | tangibleobject |
| Domain | Relationship | Range | |
|---|---|---|---|
| Label | primaryres | engage | tangibleobject |
| Properties | type: CT000142, URL: example.com + others | type: Depicts + others | + others |
| Domain | Relationship | Range | |
|---|---|---|---|
| Label | tangibleobject | type | typalconcept |
| Properties | + others | type: hasType + others | + others |
The ontology also allows for discovery of further reading based on topic (which could be a concept, heritage, historical figure, etc.) and language. Because a graph database allows for searching via relationships, even if a further reading resource is directly connected to the “Such-and-Such a Confucian academy” node, not the node for the general concept of Confucian academies, it can still be pulled up when looking for information about Confucian academies in general (and vice versa – further reading on Confucian academies in general can be brought up in relation to a specific heritage). While the examples below show only further reading, if educational events such as lectures or classes are also included, then users could be prompted with information about events related to the heritage they are visiting or researching (for example, a visitor to a Buddhist statue could be linked to events about Buddhist statues or Buddhist art in general).
Figure 31 Example showing further reading sorted by language[18]

| Domain | Relationship | Range | |
|---|---|---|---|
| Label | any | engage | digitalresource |
| Properties | type: hasFurtherReading | URI: example.com, lang: C000031 OR C000032 |
| Label | concept | concept |
| Properties | id: C000031, en: Korean | id: C000032, en: English |
Figure 32 Example showing further reading related only to heritages which are Confucian academies[19]

| Domain | Relationship | Range | |
|---|---|---|---|
| Label | any | engage | digitalresource |
| Properties | type: hasFurtherReading | URI: example.com, lang: C000031 OR C000032 |
| Domain | Relationship | Range | |
|---|---|---|---|
| Label | any | type | any |
| Properties | type: hasType | URI: example.com, en: Confucian academy |
| Label | concept | concept |
| Properties | id: C000031, en: Korean | id: C000032, en: English |
In these ways, this ontology goes beyond merely conveying interpretive information itself, but also puts such information into a context of current media and resources which make it much easier for non-experts and non-Koreans, too, to learn more about Korean cultural heritages. The inclusion in the database of media such as dramas and film which depict certain historical figures, places, or events could also be a way to bring Hallyu fans into contact with more academic information related to their media interests, and doing so in their own language (thanks to the translation and explanation features of the ontology), thus creating a bridge between media consumption and meaningful learning and academic research.
Ensuring Long-term Sustainability and Innovation
This section does not include any additional examples from the ontology because the sustainability and innovation functions have been shown through the prior examples. As shown above, the data and the interface are separate. Therefore, various interfaces can be developed to access the data in a way which does not affect the data itself, while the database can be continually enriched with more nodes, relations, translation, definitions, etc., so that the content as presented via the interface is more in depth. Furthermore, nodes, relationships, and the information contained there within can be reutilized, which means that the creation of the node and its attributes (translation, Romanization, definition, etc.) need be created only once, which reduces work in the long run. For the same reason, resources can be focused on enriching the data – adding more translations, more sources, more definitions, more relationships – rather than re-defining or re-translating nodes, or re-explaining relationships between nodes. However, unlike interpretive texts and other narrative-based interpretive mediums, because it is a database and accessed via an interface, even if data is enriched with hundreds of thousands of nodes and relationships, it does not mean that the user will be overwhelmed with too much data, because the user can select the depth and type of content they are shown.
Another benefit of this model is that information can be searched for in Korean, and displayed in English, and vice-versa. If one takes a look at the Cyphers shown in for the examples in this section, there are times when data was queries in Korean, but returned in English. If the terms have been translated once, then Korean educators, for example, can curate countless contextual “stories”– particular collections of nodes and relations - using visualization or automated text, and these can be displayed for English-speaking audiences, even if the creator of the story themselves does not speak English. This is shown in the various examples above where the query includes a term in Korean, but the results appear in English. This means more content about Korean cultural heritages can be made by Koreans for people who do not speak Korean. Furthermore, Koreans can see what areas interest non-Korean speakers by looking at the “stories” non-Koreans create.
In addition, the database plus interface design allows for potential contributions from the public – both in terms of database enrichment and interface design. For example, even university students who are not native Korean speakers could use the database as a platform to input, analyze, and display data from English-language academic sources on a particular Korean cultural heritage related topic they are interested in for a class project. Students could also engage in learn-by-doing educational activities by researching existing definitions and translations, citing them, and adding them to the database. Korean academics can also input information for their own research purposes, and since they are likely reusing nodes which have already been translated before and which have definitions, non-experts and non-Korean speakers can better understand the academic’s contributions without the academic having to make separate efforts to do so. The database could also can also be used simply as a glossary for translation. In this way, even personal uses of the database which lead to enriched data will benefit other users and the public. The information might have been initially added for the purpose of interpretation of heritages, but researchers can later use that information for these kinds of research purposes. Or vice-versa, information added for academic purposes can later be used for interpretation. In this way, you get more ‘bang for your buck’ when compared to current interpretive resources which can only be consumed passively. This approach to heritage interpretation allows for interpretive resources (in the traditional sense), plus a platform for research, plus a platform for translation, plus a platform for education. In this way, the heritage interpretation becomes more sustainable in that it minimizes redundant effort and allows for innovation – both in terms of data enrichment and interface design.
Footnotes
- ↑ Cypher: MATCH (a{ kr:'신숙주'}) MATCH (b{id:'lyndsey'}) CREATE (b)-[r:meta{type:'meta_edited', kr:'수정하였다', en:'edited', attribute:'def_en', ref:‘RS000001', create_user:'lyndsey', create_date:'20170522'}]->(a) RETURN r
- ↑ Cypher: MATCH ()-[r]-() MATCH (a{en:'presumed'}) WHERE a.id = r.ver RETURN r
- ↑ Cypher: MATCH (a{id:'T000017'})-[r:trans]->(b:tempobject) OPTIONAL RETURN r
- ↑ Cypher: MATCH (a{id:'T000017'})-[r:trans]->(b:tempobject) OPTIONAL MATCH (c) WHERE c.id = r.before OPTIONAL MATCH (d) WHERE d.id = r.ref OPTIONAL MATCH (e) WHERE e.id = r.from OPTIONAL MATCH (f) WHERE f.id = r.to OPTIONAL MATCH (g) WHERE g.id = d.source RETURN a.en as HERITAGE, r.en as ACTION, e.en as FROM, f.en as TO, CASE WHEN b.en = 'unknown' THEN c.en ELSE b.en END as DATE, g.en as REF_SOURCE
- ↑ Cypher: MATCH (a{kr:'청주향교'})-[r{type:'hasType'}]->(b); Languages are toggled in the CSS of the page
- ↑ Cypher 1: MATCH (a{kr:'청주향교'})-[r{type:'hasType'}]->(b) RETURN a.kr as HERITAGE,'(', a.ch as CHINESE1, ')','는', b.kr as HANGEUL, r.kr as RELATION; Cypher 2: MATCH (a{kr:'청주향교'})-[r{type:'hasType'}]->(b) RETURN a.en as HERITAGE, r.en as RELATION, b.rr as ROMANIZATION,'(', b.kr as HANGEUL, ')', 'i.e.', b.def_en as DEFINITION; Cypher 3: MATCH (a{kr:'청주향교'})-[r{type:'hasType'}]->(b) RETURN a.en as HERITAGE, r.en as RELATION, b.def_en as DEFINITION
- ↑ Cypher: MATCH (a{kr:'신숙주'})-[r]->(b) RETURN r
- ↑ Cypher: MATCH (a{ kr:'신숙주'})-[r]->(b) WHERE not (a)-[:name]->(b) RETURN r
- ↑ Cypher: MATCH (a{ kr:'신숙주'})-[r:name]->(b) RETURN r
- ↑ Cypher: MATCH r=(a)-[]-(b) WHERE a.kr = '청주 수천암' RETURN r
- ↑ Cypher: MATCH r=(a)-[]-(b) WHERE a.kr = '청주 수천암' OPTIONAL MATCH s=(b)-[]-(c) WHERE (a)-[:value]-(b) RETURN r, s
- ↑ Cypher: MATCH (a:tangibleobject)-[:type*1..3]->(b) WHERE b.kr = '사당' MATCH (a)-[*1..4]-(d{kr:'청주시'}) MATCH (a)-[r{type:'hasType'}]->(c) MATCH (a)-[*1..2]->(e:address) RETURN a.en as PLACE, c.en as TYPE, a.kr as NAME, e.en as ADDRESS UNION ALL MATCH (a:tangibleobject)-[:type*1..3]->(b) WHERE b.kr = '사당' MATCH (a)-[*1..4]-(d{kr:'청주시'}) MATCH (a)-[r{type:'hasType'}]->(c) MATCH (f)-[:part]->(a) MATCH (f)-[*1..2]->(e:address) RETURN f.en as PLACE, c.en as TYPE, a.kr as NAME, e.en as ADDRESS
- ↑ Kan 칸 refers to the section between pillars of a structure, and is commonly used as a way to describe the dimensions of wooden structures. Three kan across and two kan deep would mean a structure with four pillars when seen from the front, and three pillars as seen from the side.
- ↑ Cypher: MATCH (a:tangibleobject)-[:type]->(b) WHERE b.kr ENDS WITH '각' MATCH (c)-[:part|:layout]->(a) MATCH (c)-[:des]->(d) MATCH (a)-[t{type:'kan_side'}]->(e) MATCH (a)-[u{type:'kan_front'}]->(f) RETURN c.en as HERITAGE, b.en AS TYPE, b.kr as TYPE_KR, f.id as FRONT, e.id as SIDE
- ↑ Cheongju City. As uploaded on the Academy of Korean Studies English Interpretive Text Research Team Wiki. Retrieved May 2017 from http://dh.aks.ac.kr/~heritage/wiki/index.php/청주_여산송씨_정려각
- ↑ Cypher: MATCH p=(n)-[:engage]->(m) MATCH r=(m)-[:part]-(l:tangibleobject) MATCH (q{en:'photo'}) WHERE q.id= n.type RETURN p, r
- ↑ Cypher: MATCH (n)-[p:engage]->(m) MATCH (l:tangibleobject)-[r:part]->(m) MATCH (q{en:'photo'}) WHERE q.id= n.type RETURN l.en as SUPER, m.kr as SUB, n.URI as URL UNION ALL MATCH (n)-[p:engage]->(m) MATCH (m)-[r:part]->(l:tangibleobject) MATCH (q{en:'photo'}) WHERE q.id= n.type RETURN m.en as SUPER, l.kr as SUB, n.URI as URL
- ↑ Cypher: MATCH (n)-[p{type:'isFurtherReading'}]->(m) MATCH (l) WHERE l.id = n.lang RETURN m.en as TOPIC, l.en as LANG, n.URI as URL ORDER BY LANG
- ↑ Cypher: MATCH (n)-[p{type:'isFurtherReading'}]->(m) MATCH (l) WHERE l.id = n.lang MATCH (m)-[:type]->(r) WHERE r.kr = '서원' RETURN m.en as TOPIC, l.en as LANG, n.URI as URL ORDER BY LANG