"신문 제목의 구어성"의 두 판 사이의 차이
red
(→방법 및 과정) |
(→결론) |
||
| 43번째 줄: | 43번째 줄: | ||
* 구어성 관련 | * 구어성 관련 | ||
| − | ** | + | ** 결과 : 큰 차이가 없는 것으로 나타났다. |
| − | |||
---- | ---- | ||
2020년 6월 23일 (화) 16:47 판
신문 제목에 나타나는 구어성 차이
방법 및 과정
- 궁금증 : 지면 기사와 인터넷 기사 제목에서의 구성 차이가 있을까?
- 배경 이론 : 페어클로(Fairclough)는 썬지(The sun)와 공식 문서(보고서 등)의 비교를 통해 신문 기사가 대중적인 언어로의 변환 과정에서 인용과 같은 구어성을 가지고 있다고 설명한다. 본고에서는 이러한 시각을 '지면 기사-인터넷 기사'라는 새로운 대조의 관점에 적용해 보고자 한다. 보고서-신문 기사가 매체에 따른 언어의 차이가 있듯 '지면 기사-인터넷 기사' 사이의 매체에 따른 차이가 분명 있을 것이라 생각된다. [1] [2]
- 방법
- 데이터 구축
- 주제 : 이태원발 코로나 감염 사태 관련 이슈 (이태원의 2030세대의 문화, 성소수자 문제, 등교 연기, 학원 강사의 거짓말로 인한 n차 감염)
- 수집 기간 : 5/7~5/25 중 주제 관련 기사 수집[3]
- 실험 데이터
- 신문 기사 내 구어성의 차이 확인을 위해 5/25 이후 관련 주제(코로나) 지면, 인터넷 기사의 데이터를 각 20건 수집해 실험에 활용
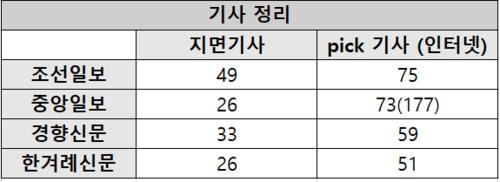
- 순서
결론

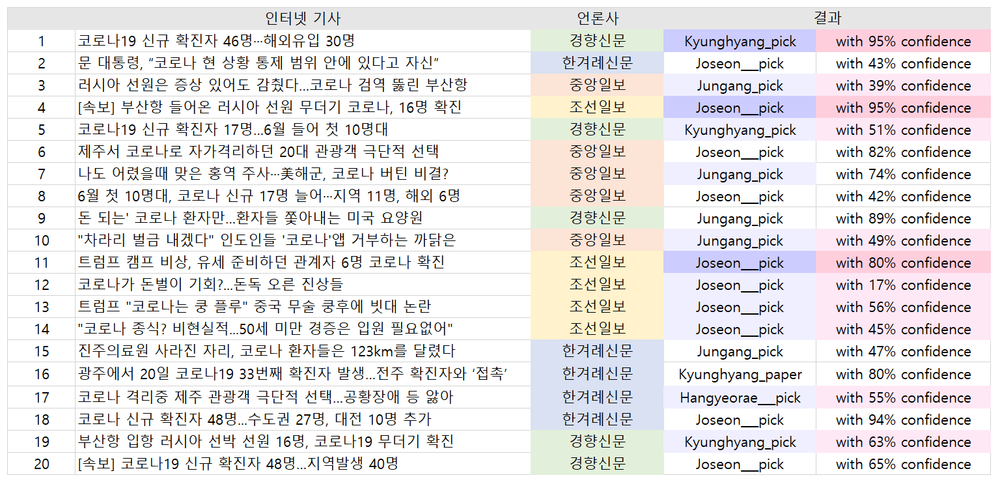
- 구어성 관련
- 결과 : 큰 차이가 없는 것으로 나타났다.
주석
- ↑ 간단하게 풀어 보자면 인터넷 기사가 상대적으로 지면 기사에 비해 가볍다거나 좀 더 직설적인 언어를 사용하는 등의 사항이 확인되는지 짚어 내고 싶었다.
- ↑ 사실상 정밀한 조사를 위해서는 지문 내용을 모두 살펴 보는 것이 맞겠지만 본 연구는 약식으로 제목에서 나타나는 차이만 살펴 보고자 한다.
- ↑ 5/25 이후에는 이태원발 코로나 감염에서 쿠팡 물류센터로 화두가 넘어간다. 본 연구는 '이태원발 코로나 감염'에 초점을 맞추고자 다음과 같이 기한을 설정했다.
- ↑ 기사 수는 임의적으로 유사하게 맞추었다. 특정 일자의 기사를 추출하기 보다는 2-3개마다 하나씩 데이터에 반영하는 방식으로 기사를 수집했다.
- ↑ 인터넷 기사의 경우 네이버에서 pick으로 제시되어 있는 기사를 수집했다. 네이버에 따르면 pick이 표시된 기사는 각 언론사가 자신의 '주요 기사'로 선정한 인터넷 기사라고 한다. 네이버 pick 관련 도움말 페이지
- 궁금증 : 지면 기사와 인터넷 기사 제목에서의 구성 차이가 있을까?
- 배경 이론 : 페어클로(Fairclough)는 썬지(The sun)와 공식 문서(보고서 등)의 비교를 통해 신문 기사가 대중적인 언어로의 변환 과정에서 인용과 같은 구어성을 가지고 있다고 설명한다. 본고에서는 이러한 시각을 '지면 기사-인터넷 기사'라는 새로운 대조의 관점에 적용해 보고자 한다. 보고서-신문 기사가 매체에 따른 언어의 차이가 있듯 '지면 기사-인터넷 기사' 사이의 매체에 따른 차이가 분명 있을 것이라 생각된다. [1] [2]
- 방법
- 데이터 구축
- 주제 : 이태원발 코로나 감염 사태 관련 이슈 (이태원의 2030세대의 문화, 성소수자 문제, 등교 연기, 학원 강사의 거짓말로 인한 n차 감염)
- 수집 기간 : 5/7~5/25 중 주제 관련 기사 수집[3]
- 실험 데이터
- 신문 기사 내 구어성의 차이 확인을 위해 5/25 이후 관련 주제(코로나) 지면, 인터넷 기사의 데이터를 각 20건 수집해 실험에 활용
- 데이터 구축

- 순서
결론
- 구어성 관련
- 결과 : 큰 차이가 없는 것으로 나타났다.
주석


- 구어성 관련
- 결과 : 큰 차이가 없는 것으로 나타났다.