"Lit Long"의 두 판 사이의 차이
red
(→Comment 논평) |
(→최수빈) |
||
| (사용자 3명의 중간 판 10개는 보이지 않습니다) | |||
| 150번째 줄: | 150번째 줄: | ||
*에든버러는 포괄적이지 않다. 비교적 쉽게 텍스트 마이닝(text-mining)을 할 수 있는 디지털화된 텍스트의 코퍼스(말뭉치)를 사용할 필요가 있었다. 또한 저작권 제한, 그리고 시각적 문자 인식과 현재의 텍스트 마이닝 기술이 시(poetry)가 가지고 있는 어려움들에 의해 제약되어 왔다. 더불어 이것은 영어와 스코틀래드어에 국한되어 왔다. – 언어 처리 도구를 게일어<ref>참고: Gaelic(스코틀랜드 켈트어) : 고대 켈트어에 뿌리를 둔 언어, 유럽 대부분 지역에서 사용되던 켈트어는 로마제국의 성장과 게르만민족의 발흥에 따라 점차 유럽 서쪽 해안으로 밀려나 어느덧 소수언어로 전락했다.</ref>에 적응시킬 수 없었다. | *에든버러는 포괄적이지 않다. 비교적 쉽게 텍스트 마이닝(text-mining)을 할 수 있는 디지털화된 텍스트의 코퍼스(말뭉치)를 사용할 필요가 있었다. 또한 저작권 제한, 그리고 시각적 문자 인식과 현재의 텍스트 마이닝 기술이 시(poetry)가 가지고 있는 어려움들에 의해 제약되어 왔다. 더불어 이것은 영어와 스코틀래드어에 국한되어 왔다. – 언어 처리 도구를 게일어<ref>참고: Gaelic(스코틀랜드 켈트어) : 고대 켈트어에 뿌리를 둔 언어, 유럽 대부분 지역에서 사용되던 켈트어는 로마제국의 성장과 게르만민족의 발흥에 따라 점차 유럽 서쪽 해안으로 밀려나 어느덧 소수언어로 전락했다.</ref>에 적응시킬 수 없었다. | ||
*The Phantom Menace | *The Phantom Menace | ||
| − | 적당한 이름은 까다롭다. 이름처럼 기능할 수 있는 흔한 명사들뿐만 아니라 장소와 개인 이름은 언어학적으로 동일한 경우가 많다. 예를 들어, 축구 감독 저스틴 에든버러가 만약 우리 책들 중 한 권에 나타난다면 우리의 코드는 아마 그를 도시 경계 근처 어딘가에 둘 것이다. 우리가 채굴한 책들에도 등장인물이 많은데, 제목들이 너무 자주 지리적으로 배치되어 있기 때문에, 우리는 가끔 사람을 장소로 잘못 읽어서 우리의 데이터베이스에 유령 항목을 생성했다. 또한 이 지명 사전은 바나 펍, 식당과 같은 종류의 장소를 포함하는데, 때때로 그것들은 The Waiting Room, the Hill Station, and the Golden Rule과 같은 일반적인 문구에서 이름을 따온다. 그래서 이것들 중 몇몇은 다른 문학적이지 않은 장소에 예상치 못한 임의의 문학적인 암시를 주면서 슬금슬금 들어왔다. | + | **적당한 이름은 까다롭다. 이름처럼 기능할 수 있는 흔한 명사들뿐만 아니라 장소와 개인 이름은 언어학적으로 동일한 경우가 많다. 예를 들어, 축구 감독 저스틴 에든버러가 만약 우리 책들 중 한 권에 나타난다면 우리의 코드는 아마 그를 도시 경계 근처 어딘가에 둘 것이다. 우리가 채굴한 책들에도 등장인물이 많은데, 제목들이 너무 자주 지리적으로 배치되어 있기 때문에, 우리는 가끔 사람을 장소로 잘못 읽어서 우리의 데이터베이스에 유령 항목을 생성했다. 또한 이 지명 사전은 바나 펍, 식당과 같은 종류의 장소를 포함하는데, 때때로 그것들은 The Waiting Room, the Hill Station, and the Golden Rule과 같은 일반적인 문구에서 이름을 따온다. 그래서 이것들 중 몇몇은 다른 문학적이지 않은 장소에 예상치 못한 임의의 문학적인 암시를 주면서 슬금슬금 들어왔다. |
*You've missed one... | *You've missed one... | ||
| − | 장소 이름의 문학적 용도를 인식하고 구성하기 위해 지명사전을 만드는 것은 어려운 일이다. 적당한 이름을 사용하여 장소를 확정하는 우리의 일반적인 방법은 상당히 다양하며, 작가들이 위치 이름을 사용하는 모든 방법을 하나의 목록에 담아내기는 쉽지 않다. 게다가, 몇몇 장소는 몇 세기 동안 여러가지의 다른 이름과 다양한 철자를 가져왔다. 그 예로, 에딘버러는 Auld Reekie, Edenborough, Edinborrow, 그리고 Embra가 될 수 있다. 그래서 찾고자 하는 것을 완전히 다른 장소와 연관된 것에서 찾을 수 있을 것이다. | + | **장소 이름의 문학적 용도를 인식하고 구성하기 위해 지명사전을 만드는 것은 어려운 일이다. 적당한 이름을 사용하여 장소를 확정하는 우리의 일반적인 방법은 상당히 다양하며, 작가들이 위치 이름을 사용하는 모든 방법을 하나의 목록에 담아내기는 쉽지 않다. 게다가, 몇몇 장소는 몇 세기 동안 여러가지의 다른 이름과 다양한 철자를 가져왔다. 그 예로, 에딘버러는 Auld Reekie, Edenborough, Edinborrow, 그리고 Embra가 될 수 있다. 그래서 찾고자 하는 것을 완전히 다른 장소와 연관된 것에서 찾을 수 있을 것이다. |
| + | |||
====도지현==== | ====도지현==== | ||
| + | <div style="text-align:center"><big>''Lit Long에서 딱 한 가지 불편한 점을 꼽자면...''</big><br/> | ||
| + | [[파일:리트롱코멘트도지현.PNG|800픽셀]]</div><br/> | ||
| + | Lit Long 사이트는 전반적으로 깔끔한 디자인과 편리한 기능을 제공해서 이용하기에 불편함이 없었다. 특히 개인 계정을 생성해서 나만의 기록을 남길 수 있도록 하는 시스템 또한 마음에 들었다. 개인적으로는 내가 만약 에든버러에 가 봤거나 에든버러를 잘 알고 있는 사람이었다면 이 사이트에 대한 만족감이 더 클 것 같다고 생각했다. (그리고 내가 영어를 좀 더 잘 하는 사람이었다면 더욱 더 큰 만족을 얻을 수 있었을 것이다!) 그러나 사이트에 회원가입을 하고 여러 기능들을 이용해 보면서 단 한 가지 불편한 점을 꼽아 보자면 상단 메뉴 바의 PATHS에서 여러 문학 경로들을 둘러볼 수 있는데, 그 경로들을 둘러볼 때의 불편함이다. 하나의 경로를 선택하면 그 경로에 포함된 펜촉 모양의 핀 맵 아이콘이 지도에 뜨고, 오른쪽에는 팝업 창으로 핀 맵으로 찍힌 위치들의 목록이 번호가 매겨진 채로 주르륵 뜨는데, 여기서 딱 하나 아쉬운 점은 이 오른쪽의 목록에서 하나를 클릭해도 맵이 이동하지 않는다는 점이다. 3번 항목을 클릭했을 때, 3번 항목이 내가 보는 화면에 띄워져 있지 않아도 맵이 전혀 이동하지 않는다. 3번 항목에 해당하는 핀 맵을 보기 위해서는 내가 이리저리 마우스를 끌어 움직여 가며 맵을 이동해서 확인해 보아야 하는 것이다. 구글 지도나 다른 상용화된 지도 시스템처럼 핀 맵을 클릭하거나 글자를 클릭했을 때 해당 핀 맵이 화면 중심으로 오도록 이동시키는 기능이 탑재되어 있었다면 좀 더 편안하게 문학 경로를 둘러볼 수 있을 것이다. 특히 이 목록이 문학 경로, 즉 PATH인 만큼 이렇게 이동을 할 수 있게 만들어 둔다면 조금 더 에든버러를 산책하는 기분, 혹은 문학을 산책하는 기분이 들지 않을까? | ||
| + | |||
====박도현==== | ====박도현==== | ||
| + | # 제작 의도와 구현된 것의 차이 | ||
| + | #* sentiment visualiser를 통해서 ''“It gives you a pie-chart breakdown and a score so you can start to get this very powerful visual sense of whether a place has been described very positively or very negatively,” says Dr Tara Thomson, a research fellow at the University of Edinburgh who has been working on the project.''를 제공하겠다고 하였는데, 인용된 글은 거리와 관련되어 있을 뿐이지 전혀 감성을 자극하거나 시각화해주지 못했다.<br/> | ||
| + | # 사용자 환경의 미흡함 | ||
| + | #* 글을 불러오거나, 원하는 장소를 찾거나, 경로를 구성하는 모든 기능을 불러오는데 시간이 많이 필요할 뿐더러 UI와 창의 배열이 지도와 글을 함께 보기엔 미흡하다. 일단 관련된 글을 다 끌고왔기 때문에 로딩시간이 길다. Text Mining을 하였든, 코퍼스의 로우 데이터를 가공해서 제공하든 사용자에게 필요한 정보 외에도 무작정 넣었기 때문에 이것이 유용하다고 하고 싶지 않다. 인문학이라고 할 수 없을 것 같다. 결국 책의 내용과 별개로 작가 소개의 역할을 하는 것 같다. | ||
| + | |||
====윤희권==== | ====윤희권==== | ||
| + | Lit Long은 사이트 자체만 놓고 보았을 때에는 사실 크게 유용하거나 어떤 연구에 사용될 수 있을 것 같다는 생각은 들지 않았다. 하지만 Lit Long은 겉으로 드러난 웹사이트일 뿐이지 실제로는 여러 작업을 거쳐서 정제된 데이터베이스라는 점에서 디지털 인문학적으로 유의미하지 않을까 생각된다. 완성된 데이터베이스만 있다면 사이트는 언제든지 바꿀 수 있는 종류의 것이고, 이러한 종류의 데이터베이스 제작 자체로 축적된 경험도 중요할 것이며 이러한 문학-지도 데이터베이스 자체는 얼마든지 더 응용될 수 있다고 생각된다. 비록 여러가지 사정이 있는지 구현되지 못한 기능들도 있었지만, 인터페이스는 깔끔했고 직관적이었으며 사용된 소프트웨어와 데이터셋 등을 공개하고 있다는 점도 중요한 것 같다. | ||
| + | |||
| + | 또한 학술적인 종류의 웹사이트가 아닐지라도 일반 대중, 특히 에든버러 주민들에게는 이러한 웹사이트가 더 유용하지 않을까 생각된다. 물론 유용성 자체가 중요한 것은 아니지만 인문학 연구를 하는 것과 동시에 일반 대중도 접근할 수 있는 결과물이 나온 것은 중요한 일이라고 여겨진다. Lit Long은 웹사이트 자체만 놓고 보자면 여행 책자같은 느낌을 주는, 혹은 다소간의 놀이에 가까운 사이트라고 생각되지만 그 제작 과정 자체는 선도적인 것이었으며 앞으로 비슷한 작업들이 이어질 수 있지 않을까 감히 추측해본다. | ||
| + | |||
====최수빈==== | ====최수빈==== | ||
| + | |||
| + | 작가나 연도, 위치, 장르 등 다양한 기준에 따라 필터링을 할 수 있고 개인 계정을 만들어 나만의 루트를 생성할 수 있는 등, 프로그램의 체계화가 굉장히 잘 되어있다. 그러나 위에 언급된 것처럼 텍스트 망닝 과정에서 오는 한계들이 그 정확도를 떨어트리는 문제가 발생하고 있다. 명칭의 혼동으로 문학적이지 않은 장소에서 문학적 의미를 부여하여 잘못 표기되거나, 명사의 기능을 혼동하여 정보화 처리를 함으로써 유령 항목을 만들어내기도 한다. 또한 하나의 대상이 여러가지의 이름을 갖고 있어서 찾고자 하는 대상으로 정확히 찾지 못하는 경우도 발생한다. 이런 문제점들은 그 대상이 사람 이름인지, 가게의 상호명인지, 일반적인 소설 문구인지 구분을 하지 못하기 때문에 발생하는 것이다. 이 한계점만 기술의 업그레이드로 보완된다면, 완벽한 프로그램이 될 것이다. | ||
2020년 4월 21일 (화) 23:29 기준 최신판
목차
Who 누가
Palimpsest
Palimpsest는 AHRC(Arts and Humanities Research Council)가 후원하고 있는 에든버러 대학의 문학, 언어, 문화 학부, 정보학부, 세인트 앤드류스 대학의 SACHI 연구 그룹, 그리고 EDINA 데이터 센터의 15개월 협력 프로젝트이다. Palimpsest 팀은 문학자, 텍스트 마이닝 전문 컴퓨터 과학자 및 정보 시각화 학자들이 포함되어 있다. 아래는 Palimpsest의 프로젝트 팀원 목록이다. [1]
- 수석 연구자
- 제임스 록슬리 James Loxley
- 에든버러 대학교 초기 근대 문학 교수
- 제임스 록슬리 James Loxley
- 공동 연구자
- 연구원과 조교
- 베아트리체 알렉스 Beatrice Alex
- 에든버러 대학교 정보학부 텍스트 마이닝 연구 연구원
- 미란다 앤더슨 Miranda Anderson
- 에든버러 대학교 영문학 연구원
- 클레어 그로버 Claire Grover
- 에든버러 대학교 정보 대학원 선임 연구원
- 데이비드 해리스-버틸 David Harris-Birtill
- SACHI의 연구 동료: 세인트 앤드류스 대학의 세인트 앤드류스 컴퓨터-인간 상호작용 연구
- 우타 힌리치 Uta Hinrichs
- SACHI의 연구 동료: 세인트 앤드류스 대학의 세인트 앤드류스 컴퓨터-인간 상호작용 연구
- 바살리스 카라이스코스 Vasalis Karaiskos
- 에든버러 대학교 정보 학부 연구원
- 니콜라 오스본 Nicola Osborne
- 에든버러 대학교 EDINA 소셜 미디어 책임자
- 리사 오티 Lisa Otty
- 에든버러 대학교 영문학 연구원
- 타라 톰슨 Tara Thompson
- 에든버러 대학교 영문학 연구 조교
- 베아트리체 알렉스 Beatrice Alex
When 언제
▲ 2015년 7월 6일에 게시된 유튜브 동영상
조사한 바, Lit Long: Edinburgh 사이트에 대한 연혁은 찾아볼 수 없었다. 다만 영국 일간지 『더 가디언(The Guardian)』에 올라온 니콜라 데이비스의 2015년 3월 28일자 기사에 따르면, Lit Long: Edinburgh은 2015년 3월 23일에 처음 런칭되었다고 한다. 이외에도 Lit Long: Edinburgh은 에든버러 대학 신문 『EDIT Magazine』의 2015년 여름호에서 소개된 바 있다.
Where 어디서
에든버러 대학교, 세인트 앤드류스 대학교
Lit Long의 배경 지역, 에든버러
What 무엇을
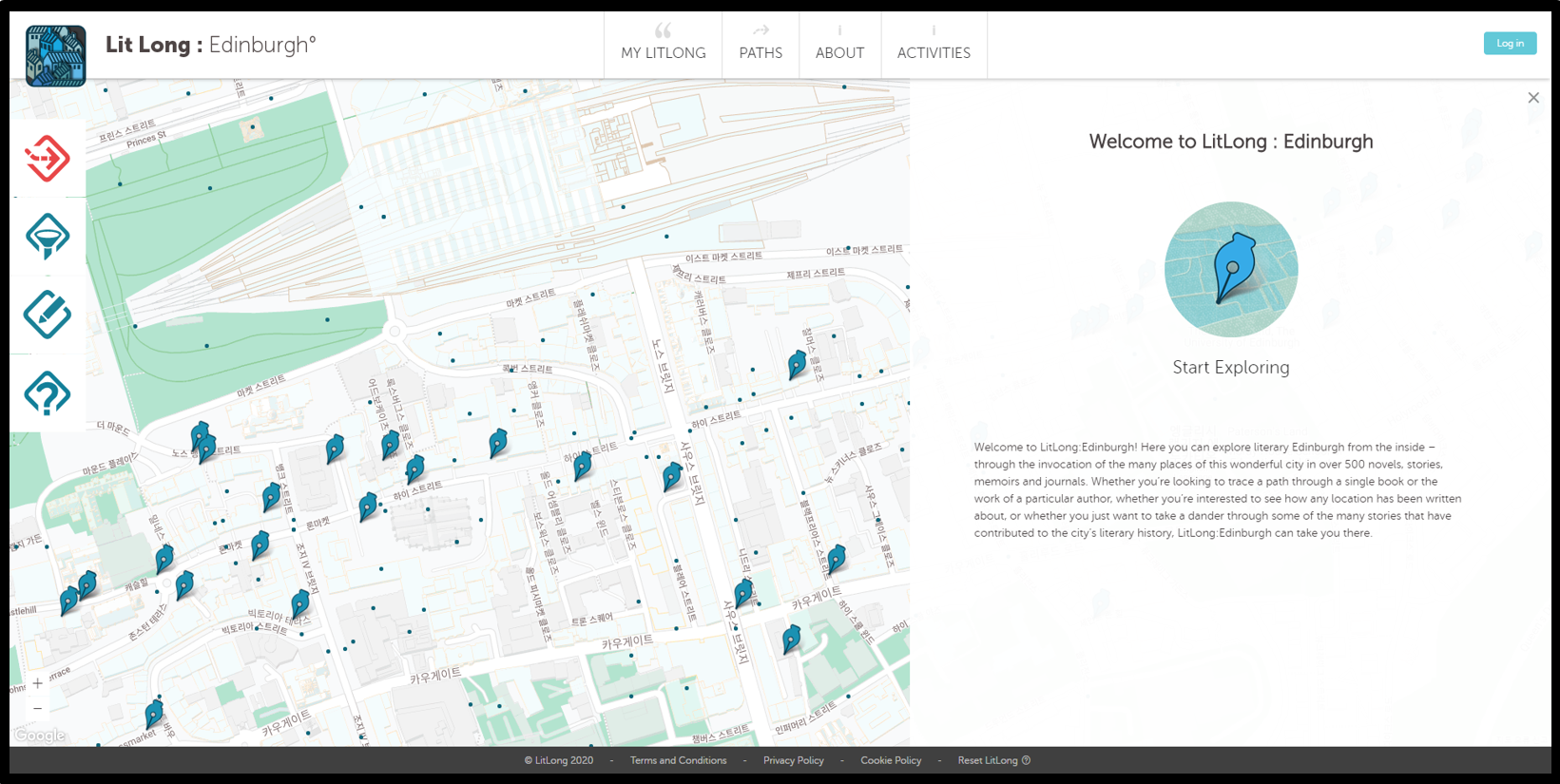
- 'Lit-Long'은 문학 에든버러의 독특한 지도다. 그 뒤에는 약 600권의 책(소설, 단편, 편지, 회고록)에서 발췌한 매우 큰 데이터베이스가 있다. 발췌문에는 에든버러에 있는 장소의 이름이 사용되어 있다는 특징이 있으며, 각각의 장소에는 좌표를 부여하고 지도에 고정할 수 있다.
- 또한 이 데이터베이스는 최신 기술을 사용하여 작성되었다. 조금 더 구체적으로 말하자면, Lit Long은 에든버러에서 설정된 문학 작품을 텍스트로 작성하고 결과를 접근 가능한 방식으로 시각화하기 위해 문학 학자들의 정보를 통해 얻은 자연어 처리 기술을 사용했다.
How 어떻게
- LitLong:Edinburgh는 영국 국립 도서관, 스코틀랜드 국립 도서관, 하티 트러스트 디지털 도서관 등에서 제공받은 방대한 디지털 서적들에 텍스트 마이닝과 지리참조(Georeference)를 사용해 탄생했다. 추가적으로, 몇몇 출판사들과 작가들이 자신들의 목록을 공유해 주기도 했다. 방대한 장서 속에서 지명의 사용 빈도와 범위를 통해 에든버러가 그 책의 배경임을 알 수 있는 텍스트들을 찾아내려고 했으며, 알고리즘과 수동 선별 작업의 혼용 끝에 기준에 맞는 텍스트들을 선별해 도시의 탐구나 실제 활동의 배경으로 이용될 수 있는 데이터셋을 얻을 수 있었다. 또한 지명들은 픽션이나 회고록에서 어떤 장소가 언급될 수 있는 수많은 방식들을 고려해서 제작된 맞춤형 지명 사전을 통해 지도에 등록되었다.
계정 생성


- 특이하게도 Lit Long 홈페이지는 계정생성을 지원하고 있다. 계정 생성 절차는 간단하다. 누구든지 구글 계정이나 페이스북 계정이 있다면 간편하게 가입할 수 있으며, 다른 e-mail 주소를 이용해서도 사이트에 회원가입할 수 있다. 계정 생성 후에는 사이트 오른쪽 상단을 클릭해서 프로필 사진과 닉네임을 설정할 수 있다.
MY LITLONG

- Lit Long이 계정 생성을 지원하고 있기 때문에, 누구나 회원가입만 하면 'MY LITLONG' 카테고리를 이용할 수 있다. MY LITLONG 카테고리는 'MY AUTHORS', 'MY LIBRARY', 'MY PATHS' 세 개의 세부 카테고리로 나뉘어지며, MY AUTHORS에서는 내가 저장한 발췌문의 저자를, MY LIBRARY에서는 내가 저장한 발췌문의 원 저서를, MY PATHS에서는 내가 만든 PATHS나 내가 복사해 온 PATHS를 한눈에 볼 수 있다.

- 발췌문을 MY LIBRARY에 저장하는 방법은 간단하다. 지도에서 펜촉 모양의 아이콘을 클릭한 뒤 뜨는 팝업창에서 붉은 색의 'SAVE EXCERPT TO LIBRARY(발췌문을 내 라이브러리에 저장하기)' 버튼을 클릭하면 버튼이 'REMOVE EXCERPT FROM LIBRARY(발췌문을 내 라이브러리에서 삭제하기)'로 바뀌면서 라이브러리에 바로 저장이 된다. 이때 'REMOVE EXCERPT FROM LIBRARY(발췌문을 내 라이브러리에서 삭제하기)' 버튼을 누르게 되면 내 라이브러리에 저장되어 있던 발췌문이 삭제된다.
Paths

- 메뉴 막대에서
 (PATHS 아이콘)를 눌러 새 경로를 만들거나, 저장된 경로를 보고, 추천 경로 및 다른 사용자가 만든 경로를 탐색하거나,
(PATHS 아이콘)를 눌러 새 경로를 만들거나, 저장된 경로를 보고, 추천 경로 및 다른 사용자가 만든 경로를 탐색하거나,  아이콘을 눌러 무작위로 발췌문들을 이은 경로를 만들 수 있다. 언제든지
아이콘을 눌러 무작위로 발췌문들을 이은 경로를 만들 수 있다. 언제든지  아이콘을 누르면 시작 페이지로 돌아갈 수 있다.
아이콘을 누르면 시작 페이지로 돌아갈 수 있다.





- 또한 위의 사진처럼 'READ ABOUT THE AUTHOR' 버튼을 누르면 발췌문의 작가에 관련한 정보가 새 창으로 뜨고, 'READ THIS BOOK' 버튼을 누르면 발췌문의 원 저서에 관련한 정보가 새 창으로 뜬다.
나만의 PATH만들기
 일련의 발췌문을 연결하는 나만의 경로(PATH)를 만들려면
일련의 발췌문을 연결하는 나만의 경로(PATH)를 만들려면
- 가장 먼저
 버튼을 클릭한다.
버튼을 클릭한다. - 이 아이콘이
 와 같이 빨간색일 동안에는 나만의 경로(PATH)만들기 모드이므로 이때 지도의 펜촉 아이콘을 클릭한다.
와 같이 빨간색일 동안에는 나만의 경로(PATH)만들기 모드이므로 이때 지도의 펜촉 아이콘을 클릭한다. - 펜촉 아이콘을 클릭하면 뜨는 팝업에서 'ADD EXCERPT TO PATH(발췌문을 경로에 저장하기)' 버튼을 클릭한다.
 버튼을 누르면 언제든지 현재 경로를 편집할 수 있다.
버튼을 누르면 언제든지 현재 경로를 편집할 수 있다.- 경로 편집이 완료되면 저장 단추를 클릭하여 나의 경로 라이브러리에 저장한다.
- Lit Long 모바일 앱을 사용하면 이 경로를 실시간으로 따라갈 수 있다.
- 나중에 MY LITLONG 카테고리의 MY PATH로 이동하여 경로를 편집할 수 있다.
- 또한 다른 사용자와 함께 즐길 수 있도록 경로를 퍼블릭 게시할 수 있다.
- 또한 다른 사용자와 함께 즐길 수 있도록 경로를 퍼블릭 게시할 수 있다.



Filter
 버튼을 눌러서 펜촉 모양의 맵 핀을 필터링할 수 있다. 저자, 책 제목, 키워드, 장르, 저자 성별 또는 기간별로 필터를 설정할 수 있으며 특정 항목은 슬라이더를 사용하면 더 많거나 적은 핀이 보이도록 할 수 있다..
버튼을 눌러서 펜촉 모양의 맵 핀을 필터링할 수 있다. 저자, 책 제목, 키워드, 장르, 저자 성별 또는 기간별로 필터를 설정할 수 있으며 특정 항목은 슬라이더를 사용하면 더 많거나 적은 핀이 보이도록 할 수 있다..- 장르에 따른 필터링


- 발췌문의 원 저서의 장르에 따라 펜촉 모양의 맵 핀을 필터링할 수 있도록 설정되어 있다. Lit Long에서 분류하고 있는 장르는 다음과 같다.
- adventure (모험)
- anthology (시집)
- autobiography (자서전)
- biography (전기)
- biography and autobiography (전기 및 자서전)
- children's fiction (어린이 소설)
- classic fiction (고전 소설)
- crime and mystery (범죄와 미스터리)
- essays and journals (수필과 저널)
- fiction (소설)
- historical fiction (역사 소설)
- history (역사)
- horror and ghost stories (공포와 유령 이야기)
- humour and satire (유머와 풍자)
- letters and diaries (편지와 일기)
- myths and legends (신화와 전설)
- non-fiction (논픽션)
- poetry (시)
- romance (로맨스)
- sagas (서사시)
- science fiction (공상 과학)
- short stories (단편)
- thrillers and suspense (스릴러와 서스펜스)
- travel (여행)
- urban fiction (도시 소설)
- war fiction (전쟁 소설)
- 발췌문의 원 저서의 장르에 따라 펜촉 모양의 맵 핀을 필터링할 수 있도록 설정되어 있다. Lit Long에서 분류하고 있는 장르는 다음과 같다.
- 저자에 따른 필터링

- 발췌문의 원 저서의 작가에 따라 펜촉 모양의 맵 핀을 필터링할 수 있도록 설정되어 있다.
- 저자의 성별에 따른 필터링

- 발췌문의 원 저서의 작가의 성별에 따라 펜촉 모양의 맵 핀을 필터링할 수 있도록 설정되어 있다.
- 연도에 따른 필터링

- 슬라이더를 이용해 발췌문의 원 저서가 출판된 연도에 따라 펜촉 모양의 맵 핀을 필터링할 수 있도록 설정되어 있다.
- 위치에 따른 필터링

- 슬라이더로 선택한 숫자만큼 펜촉 모양의 맵 핀을 필터링할 수 있도록 설정되어 있다.
- 랜덤 필터링

- 완전히 랜덤으로 맵 핀을 필터링할 수 있도록 설정되어 있다.
그 외
발췌문

스코틀랜드 의회
- 지도에서 펜촉 모양의 아이콘(맵 핀)을 클릭하면 해당 위치를 언급한 책의 발췌문이 나오며 책의 전문을 읽을 수 있는 링크 또한 제공된다.
- 파란색 펜촉의 경우 그 위치가 맞지만 노란색 펜촉은 그 위치와는 상관없이 에든버러 자체가 언급될 경우에 쓰인다.
Why 왜
우리가 Lit Long을 만든 목적은 '아주 많은 양의 책을 디지털로 읽을 수 있다면 에든버러와 같은 문학적인 도시의 지형이 어떻게 보일지 알아보기 위함'이었다. 에든버러는 잘 알려진 문학사를 가지고 있으며, 이는 수많은 작가들과 독자들에 의해 수년간 누적되어 정리되어왔다. 실제로 이 역사는 책, 지도, 도보 여행 및 도시의 많은 문학 관련 유적지와 관광 명소에서 찾아볼 수 있다. 그러나 수많은 사람들의 집단지성을 통해서라면 우리는 또 다른, 우리에게는 생소한 이야기들을 찾아낼 수 있을지도 모른다. 따라서 우리는 알고리즘이 독서를 할 수 있도록 설정함으로써 에든버러의 문학사에 대한 친숙한 이야기를 수백 편의 다른 작품들의 생소한 맥락과 연결할 수 있도록 노력했다. 우리는 이 지도와 앱이 우리가 포착할 수 있었던 수백 개의 문학 작품들의 오래된 연결고리들을 설명하고 더 나아가 새로운 연결을 만들어 내길 원한다.
Comment 논평
한계
- 에든버러는 포괄적이지 않다. 비교적 쉽게 텍스트 마이닝(text-mining)을 할 수 있는 디지털화된 텍스트의 코퍼스(말뭉치)를 사용할 필요가 있었다. 또한 저작권 제한, 그리고 시각적 문자 인식과 현재의 텍스트 마이닝 기술이 시(poetry)가 가지고 있는 어려움들에 의해 제약되어 왔다. 더불어 이것은 영어와 스코틀래드어에 국한되어 왔다. – 언어 처리 도구를 게일어[3]에 적응시킬 수 없었다.
- The Phantom Menace
- 적당한 이름은 까다롭다. 이름처럼 기능할 수 있는 흔한 명사들뿐만 아니라 장소와 개인 이름은 언어학적으로 동일한 경우가 많다. 예를 들어, 축구 감독 저스틴 에든버러가 만약 우리 책들 중 한 권에 나타난다면 우리의 코드는 아마 그를 도시 경계 근처 어딘가에 둘 것이다. 우리가 채굴한 책들에도 등장인물이 많은데, 제목들이 너무 자주 지리적으로 배치되어 있기 때문에, 우리는 가끔 사람을 장소로 잘못 읽어서 우리의 데이터베이스에 유령 항목을 생성했다. 또한 이 지명 사전은 바나 펍, 식당과 같은 종류의 장소를 포함하는데, 때때로 그것들은 The Waiting Room, the Hill Station, and the Golden Rule과 같은 일반적인 문구에서 이름을 따온다. 그래서 이것들 중 몇몇은 다른 문학적이지 않은 장소에 예상치 못한 임의의 문학적인 암시를 주면서 슬금슬금 들어왔다.
- You've missed one...
- 장소 이름의 문학적 용도를 인식하고 구성하기 위해 지명사전을 만드는 것은 어려운 일이다. 적당한 이름을 사용하여 장소를 확정하는 우리의 일반적인 방법은 상당히 다양하며, 작가들이 위치 이름을 사용하는 모든 방법을 하나의 목록에 담아내기는 쉽지 않다. 게다가, 몇몇 장소는 몇 세기 동안 여러가지의 다른 이름과 다양한 철자를 가져왔다. 그 예로, 에딘버러는 Auld Reekie, Edenborough, Edinborrow, 그리고 Embra가 될 수 있다. 그래서 찾고자 하는 것을 완전히 다른 장소와 연관된 것에서 찾을 수 있을 것이다.
도지현

Lit Long 사이트는 전반적으로 깔끔한 디자인과 편리한 기능을 제공해서 이용하기에 불편함이 없었다. 특히 개인 계정을 생성해서 나만의 기록을 남길 수 있도록 하는 시스템 또한 마음에 들었다. 개인적으로는 내가 만약 에든버러에 가 봤거나 에든버러를 잘 알고 있는 사람이었다면 이 사이트에 대한 만족감이 더 클 것 같다고 생각했다. (그리고 내가 영어를 좀 더 잘 하는 사람이었다면 더욱 더 큰 만족을 얻을 수 있었을 것이다!) 그러나 사이트에 회원가입을 하고 여러 기능들을 이용해 보면서 단 한 가지 불편한 점을 꼽아 보자면 상단 메뉴 바의 PATHS에서 여러 문학 경로들을 둘러볼 수 있는데, 그 경로들을 둘러볼 때의 불편함이다. 하나의 경로를 선택하면 그 경로에 포함된 펜촉 모양의 핀 맵 아이콘이 지도에 뜨고, 오른쪽에는 팝업 창으로 핀 맵으로 찍힌 위치들의 목록이 번호가 매겨진 채로 주르륵 뜨는데, 여기서 딱 하나 아쉬운 점은 이 오른쪽의 목록에서 하나를 클릭해도 맵이 이동하지 않는다는 점이다. 3번 항목을 클릭했을 때, 3번 항목이 내가 보는 화면에 띄워져 있지 않아도 맵이 전혀 이동하지 않는다. 3번 항목에 해당하는 핀 맵을 보기 위해서는 내가 이리저리 마우스를 끌어 움직여 가며 맵을 이동해서 확인해 보아야 하는 것이다. 구글 지도나 다른 상용화된 지도 시스템처럼 핀 맵을 클릭하거나 글자를 클릭했을 때 해당 핀 맵이 화면 중심으로 오도록 이동시키는 기능이 탑재되어 있었다면 좀 더 편안하게 문학 경로를 둘러볼 수 있을 것이다. 특히 이 목록이 문학 경로, 즉 PATH인 만큼 이렇게 이동을 할 수 있게 만들어 둔다면 조금 더 에든버러를 산책하는 기분, 혹은 문학을 산책하는 기분이 들지 않을까?
박도현
- 제작 의도와 구현된 것의 차이
- sentiment visualiser를 통해서 “It gives you a pie-chart breakdown and a score so you can start to get this very powerful visual sense of whether a place has been described very positively or very negatively,” says Dr Tara Thomson, a research fellow at the University of Edinburgh who has been working on the project.를 제공하겠다고 하였는데, 인용된 글은 거리와 관련되어 있을 뿐이지 전혀 감성을 자극하거나 시각화해주지 못했다.
- sentiment visualiser를 통해서 “It gives you a pie-chart breakdown and a score so you can start to get this very powerful visual sense of whether a place has been described very positively or very negatively,” says Dr Tara Thomson, a research fellow at the University of Edinburgh who has been working on the project.를 제공하겠다고 하였는데, 인용된 글은 거리와 관련되어 있을 뿐이지 전혀 감성을 자극하거나 시각화해주지 못했다.
- 사용자 환경의 미흡함
- 글을 불러오거나, 원하는 장소를 찾거나, 경로를 구성하는 모든 기능을 불러오는데 시간이 많이 필요할 뿐더러 UI와 창의 배열이 지도와 글을 함께 보기엔 미흡하다. 일단 관련된 글을 다 끌고왔기 때문에 로딩시간이 길다. Text Mining을 하였든, 코퍼스의 로우 데이터를 가공해서 제공하든 사용자에게 필요한 정보 외에도 무작정 넣었기 때문에 이것이 유용하다고 하고 싶지 않다. 인문학이라고 할 수 없을 것 같다. 결국 책의 내용과 별개로 작가 소개의 역할을 하는 것 같다.
윤희권
Lit Long은 사이트 자체만 놓고 보았을 때에는 사실 크게 유용하거나 어떤 연구에 사용될 수 있을 것 같다는 생각은 들지 않았다. 하지만 Lit Long은 겉으로 드러난 웹사이트일 뿐이지 실제로는 여러 작업을 거쳐서 정제된 데이터베이스라는 점에서 디지털 인문학적으로 유의미하지 않을까 생각된다. 완성된 데이터베이스만 있다면 사이트는 언제든지 바꿀 수 있는 종류의 것이고, 이러한 종류의 데이터베이스 제작 자체로 축적된 경험도 중요할 것이며 이러한 문학-지도 데이터베이스 자체는 얼마든지 더 응용될 수 있다고 생각된다. 비록 여러가지 사정이 있는지 구현되지 못한 기능들도 있었지만, 인터페이스는 깔끔했고 직관적이었으며 사용된 소프트웨어와 데이터셋 등을 공개하고 있다는 점도 중요한 것 같다.
또한 학술적인 종류의 웹사이트가 아닐지라도 일반 대중, 특히 에든버러 주민들에게는 이러한 웹사이트가 더 유용하지 않을까 생각된다. 물론 유용성 자체가 중요한 것은 아니지만 인문학 연구를 하는 것과 동시에 일반 대중도 접근할 수 있는 결과물이 나온 것은 중요한 일이라고 여겨진다. Lit Long은 웹사이트 자체만 놓고 보자면 여행 책자같은 느낌을 주는, 혹은 다소간의 놀이에 가까운 사이트라고 생각되지만 그 제작 과정 자체는 선도적인 것이었으며 앞으로 비슷한 작업들이 이어질 수 있지 않을까 감히 추측해본다.
최수빈
작가나 연도, 위치, 장르 등 다양한 기준에 따라 필터링을 할 수 있고 개인 계정을 만들어 나만의 루트를 생성할 수 있는 등, 프로그램의 체계화가 굉장히 잘 되어있다. 그러나 위에 언급된 것처럼 텍스트 망닝 과정에서 오는 한계들이 그 정확도를 떨어트리는 문제가 발생하고 있다. 명칭의 혼동으로 문학적이지 않은 장소에서 문학적 의미를 부여하여 잘못 표기되거나, 명사의 기능을 혼동하여 정보화 처리를 함으로써 유령 항목을 만들어내기도 한다. 또한 하나의 대상이 여러가지의 이름을 갖고 있어서 찾고자 하는 대상으로 정확히 찾지 못하는 경우도 발생한다. 이런 문제점들은 그 대상이 사람 이름인지, 가게의 상호명인지, 일반적인 소설 문구인지 구분을 하지 못하기 때문에 발생하는 것이다. 이 한계점만 기술의 업그레이드로 보완된다면, 완벽한 프로그램이 될 것이다.- ↑ 출처: https://ahrc.ukri.org/newsevents/events/calendar/litlongedinburgh/
- ↑ 인식론자(Epistemics)는 1969년 에든버러 대학 (Edinburgh University)이 주창한 '인식론 학교(School of Epistemics)'를 기초로 만들어진 용어이다. epistemology(인식론)은 지식에 대한 철학적 이론인 반면 epistemics(에든버러 대학의 인식론)은 지식에 대한 과학적 연구를 의미한다는 점에서 epistemology(인식론적 의미)와 구별된다. (이하 등장하는 ‘인식론’은 epistemics를 의미함.) 인식론은 또한 인지과학과 비교된다. 크리스토퍼 룽쥐 히긴스 (Christopher Longuet-Higgins)는 그것을 “지식과 이해가 성취되고 전달되는 지각, 지적 및 언어적 프로세스의 공식적인 모델 구축”이라고 정의했다. 1978년 에세이 “Epistemics: 인식의 규제 이론”에서 알빈 J. 골드만 (Alvin J. Goldman)은 인식론의 방향성을 설명하기 위해 "인식론적(epistemics)"이라는 용어를 만들었다고 주장한다. 골드만은 그의 인식론이 전통적인 인식론과 계속 이어지고 있으며, 새로운 용어는 단지 반대를 피하기 위한 것이라고 주장한다. 골드만의 버전에서 인식론자의 인식론은 인지 심리학과의 결합한다는 점에서 전통적 인식론과는 조금 다르다. 인식론(epistemics)은 지식이나 신념으로 이어지는 정신적 과정과 정보 처리 메커니즘에 대한 상세한 연구를 강조한다. (출처: https://educalingo.com/ko/dic-en/epistemics)
- ↑ 참고: Gaelic(스코틀랜드 켈트어) : 고대 켈트어에 뿌리를 둔 언어, 유럽 대부분 지역에서 사용되던 켈트어는 로마제국의 성장과 게르만민족의 발흥에 따라 점차 유럽 서쪽 해안으로 밀려나 어느덧 소수언어로 전락했다.