"Eighteenth Century Poetry Archive"의 두 판 사이의 차이
red
(→Comment 논평) |
(→Comment 논평) |
||
| (같은 사용자의 중간 판 하나는 보이지 않습니다) | |||
| 163번째 줄: | 163번째 줄: | ||
18세기 시 아카이브는, 해당 아카이브가 코퍼스 자료를 가져온 ECCO-TCP 데이터 베이스와 비교하면, UI/UX가 훨씬 편리하게 잘 구축되어 있다. 시인 별로, 시대 별로, 심지어는 주제와 장르 별로 시를 분류한 것은 자료를 접근하는 데에 훨씬 편리하게 느껴졌다. 그리고 단순히 시와 시인 만을 제시하는 것이 아니라, 믿음직한 참고문헌들에서 추가적인 정보를 추가해서 이를 공부하는 학생들에게 도움이 될 것으로 보인다. 그리고 여러 디지털 시각화 자료들을 사용한 점도 흥미로웠다. 단순한 언어학적 분석부터, 외부의 도구를 사용한 시각화까지 제공해서, 시의 텍스트만 보는 것을 넘어서서, 디지털이라는 장점을 활용해서 시에 대한 더 넓은 시각의 다양한 경험을 제공한 것은 특기할만 하다. 전반적으로 시라는 문학 작품을 다양한 디지털 도구를 사용해서 고차원적인 데이터 베이스를 만들어 낸 것으로 보인다. | 18세기 시 아카이브는, 해당 아카이브가 코퍼스 자료를 가져온 ECCO-TCP 데이터 베이스와 비교하면, UI/UX가 훨씬 편리하게 잘 구축되어 있다. 시인 별로, 시대 별로, 심지어는 주제와 장르 별로 시를 분류한 것은 자료를 접근하는 데에 훨씬 편리하게 느껴졌다. 그리고 단순히 시와 시인 만을 제시하는 것이 아니라, 믿음직한 참고문헌들에서 추가적인 정보를 추가해서 이를 공부하는 학생들에게 도움이 될 것으로 보인다. 그리고 여러 디지털 시각화 자료들을 사용한 점도 흥미로웠다. 단순한 언어학적 분석부터, 외부의 도구를 사용한 시각화까지 제공해서, 시의 텍스트만 보는 것을 넘어서서, 디지털이라는 장점을 활용해서 시에 대한 더 넓은 시각의 다양한 경험을 제공한 것은 특기할만 하다. 전반적으로 시라는 문학 작품을 다양한 디지털 도구를 사용해서 고차원적인 데이터 베이스를 만들어 낸 것으로 보인다. | ||
| + | 하지만 아쉬운 점이 몇 가지 있다. 우선, '''근원적으로 왜 18세기 시를 주제로 아카이브를 만들었는지에 대한 설명이 부족하다.''' 이 아카이브의 관리자의 전공과 관심사가 18세기 시이기 때문에 이 프로젝트를 진행한 것이다. 물론 영미시사에서 18세기가 신고전주의에서 낭만주의로 넘어가며 주요 시인들을 많이 배출한 중요한 시기이기는 하지만, 그에 관한 추가적인 설명이 있었다면, 꼭 18세기를 연구하는 학자들 뿐만 아니라 다른 시대나 종류의 문학에 관심이 있는 더 많은 사람들도 이 아카이브의 필요성과 중요성을 인식할 수 있을 것 같다는 생각이 들었다. 아마 이 프로젝트의 확장으로 18, 19세기가 중심이 되는 낭만주의 시 아카이브인 Romantic-Period Poetry Archive를 현재 구축하고 있으며, 이 프로젝트에는 전 세계의 시와 시인을 포함해서 지도 상에 나타내는 작업도 진행하고 있다. | ||
| − | + | 또한, 결국 '''시에 대한 분석이 디지털 도구를 활용한 언어학적 분석에서 그치는 것이 아쉬웠다.''' 이 데이터 베이스가 그래도 일반 아카이브보다 발전한 부분은 다양한 분석과 시각화 도구를 제공한다는 것이다. 그러나, 각 한 편 한 편을 언어학적인 분석 알고리즘에 넣는 것에 그치는 것이 아쉬웠다. 만약 기본 시 텍스트 데이터를 태깅 작업을 하는 식으로 좀 더 가공하거나, 아카이브에 구축된 전체 시에 관한 간단한 코퍼스 분석이라도 이루어졌거나, 이루어질 수 있는 환경이라면 더 풍부한 학술적 공간이 되었을 것이라고 생각한다. 이 아카이브에서 시의 형식에 대한 가까이 읽기는 가능하지만, 시의 의미를 파악하기에는 부족하다고 느꼈다. 지식 모델링을 제공하기는 하지만, 아직까지 이 아카이브의 관리자가 업로드한 모델만 적게 존재하는 점(필자는 Thomas Gray의 Imitation에 대한 지식 그래프 하나만 발견했다)도 아쉽다. | |
| − | + | ''(류인태 교수님 논평 추가)'' 하지만 이런 언어학적 분석은 현재 연구자들 사이에서 활발하게 이루어지지 않고 있기 때문에, 해당 아카이브에서 이를 제공한다는 의의가 있다. 문학 연구에서는 시의 맥락과 의미 등을 파악하는 연구를 주로 하고, 언어학자들은 언어학적 관점에서의 문학 연구를 통해 문학적 관점에 맞는 결과를 낼 수 없으므로 잘 시도하지 않는다. 그래서 이러한 연구적 공백을 이 아카이브에서 다양한 디지털 방법을 활용해서 메꿨다고 볼 수도 있다. 또한, 이러한 언어학적 분석을 이미 기존에 있었던 자료와 도구들을 사용해서 실행했다는 점도 주목할 만하다. 이는 디지털 인문학 연구에서 기초 자원의 중요성을 보여주는 사례이다. 또한, 지식 모델링 설계는 설계하는 과정에서 데이터를 선택하고, 구축하며 연구자의 주관적인 입장이 들어갈 수도 있기 때문에 객관화, 보편화 하기는 어려운 자료라는 지적을 받는다. 그러므로, 해당 아카이브에서는 관리자가 직접 지식 그래프를 설계해서 제공하는 것이 아니라, 관리자는 샘플 정도만 제공하고, 사용자들이 자유롭게 각자의 관점에 맞게 지식 모델링을 구현하고 이를 공유할 수 있도록 해놓았다. 이는 시에 대한 객관적인 분석과 각 사용자가 보는 시에 대한 주관적인 관점을 해치지 않고, 사용자들이 자유롭게 지식 그래프 구현에 참여해서 이를 공유하고 의견을 나누는 협업의 장을 만든다는 데에도 큰 의의가 있다. | |
| − | |||
2022년 3월 23일 (수) 11:59 기준 최신판
Who 누가

- 前) 영국 University of Oxford의 Bodleian Libraries의 디지털 사서(Digital Librarian)
- 영문학을 기반으로 한 디지털 인문학자
- 주요 학문 분야: 18세기 영문 장편시, 낭만주의, Thomas Gray 등
- 기술 분야: XML 기술, 시맨틱 웹(Semantic Web), 메타데이터 프레임워크(metadata frameworks), LOD, 전자출판 프레임워크(electronic publishing frameworks), 텍스트 인코딩(text encoding), NLP 도구, 시각화(visualizations), 지식 모델링(knowledge modelling) 등
- 진행 프로젝트: Thomas Gray Archive (TGA), Eighteenth-Century Poetry Archive (ECPA), Romantic Period Poetry Archive (RPPA) (진행 중)
- Oxford University의 디지털 사서(Digital Librarian)이자, 대학 내 Taylor Institution Library에서 독일어 주제 담당 사서(Subject Librarian)
- United Kingdom Office for Library and Information Networking(UKOLN), Work Package 리더, IMPACT 프로젝트, 옥스포드 대학 Early English Books Online(EEBO) 리뷰어
- 관련 프로젝트: The Shakespeare Quartos Archive Thomas Gray Archive (TGA), Eighteenth-Century Poetry Archive (ECPA)
위 연구자들이 중심이 되어서, 18세기 시 분야의 선생님, 연구자, 학생들과 함께 협업으로 진행한 연구 프로젝트
When 언제
| 시간 | 작업 |
|---|---|
| 2006 | 작은 프로젝트를 시작했던 것이 결국 Eighteenth Century Poetry Archive로 이어짐. 시인 Thomas Gray를 중심으로 그와 동시대의 시인들의 생애와 작품을 다루는 Thomas Gray Archive를 만들다 보니 규모가 커짐 |
| 2008 | 발전한 디지털 문학 연구와 인문학 컴퓨팅에 힘입어서, 그리고 또 거기에 기여하기 위해서 더 광범위한 프로젝트를 하기 위한 제대로 된 아이디어를 구상하기 시작함. 한창 진행 중이었던 옥스퍼드 대학의 ECCO-TCP와 컴퓨터를 활용한 문학 비평에 대한 초기의 여러 실험들에 도움을 받음 |
| 2012년 겨울 | 본격적으로 ECPA를 개발 시작 |
| 2015년 겨울 | 알파 버전의 웹사이트를 완성 |
| 2016년 5월 1일 ~ 2019년 5월 1일 | 베타 단계의 ECPA 진행. 2018년에 British Society for Eighteenth-Century Studies의 Digital Prize Winner로 선정됨 |
| 2019년 여름 (v1.1) | 3002편의 작품, 316명의 작가. 지식 모델링(knowledge modelling) 프로토타입 도입 |
| 2019~20년 겨울 (v1.2) | 3051편의 작품, 319명의 작가. 일종의 18세기 학술 정보 검색 엔진인 18thConnect [2] 에 참여 |
| 2020년 여름 (v1.3) | 3105편의 작품, 320명의 작가. POSTDATA [3] 의 코퍼스 리더와 다운로더에 등록됨 |
| 2020~21년 겨울 (v1.4) | 3199편의 작품, 324명의 작가. |
| 2021년 여름 (v1.5) | 3200편의 작품, 324명의 작가. OpenSeadragon이라는 고해상도의 오픈 소스 이미지 뷰어 서비스를 사용하기 시작. |
| 2021~22년 겨울 (v1.6) | 3212 편의 작품, 328명의 작가. 코퍼스 방면에서 전문(full-text) 검색과 여러 검색 패킷(search facets)를 통한 시 형태의 인코딩 등을 활용하는 최신식의 검색 엔진 구축. 2022년 3월 현재까지 계속해서 작품과 시인을 업데이트하는 중. |
Where 어디서

영국 옥스퍼드 대학의 도서관으로, 대학에 속한 연구 도서관 및 학부와 교육기관의 도서관들 총 27개의 도서관들을 Bodleian Libraries로 통합하여 칭한다. 영국에서 가장 큰 학술 도서관이며, 유럽에서 가장 큰 도서관 중 하나이다. 그 중 Bodleian Library는 주도서관으로, 지어진지 400년이 넘었다. Bodleian Libraries에는 전체 1,300만부가 넘는 인쇄 자료들과 80,000부가 넘는 e-journal들을 소유하고 있으며, 희귀 도서, 자료, 고문서, 지도, 음악, 예술 작품, 그 외 다양한 발견물들을 포함한 특별한 컬렉션을 다량 보유하고 있다.

2015년부터 Bodleian Libraries의 귀중 자료 컬렉션을 전세계에서 교육과 학습의 목적으로 온라인에서 접근하고 이용할 수 있도록 만든 디지털 서비스이다. 도서관이 소장하는 고문서, 지도, 사진, 초상화, 희귀책 등 다양한 자료들을 온라인으로 볼 수 있다. Bodleian Libraries는 1900년대 초기부터 소장 자료들을 디지털화하기 시작했으며, 이는 도서관 소장 자료들을 더 많은 사람들에게 접근 가능하게 만들었다. 2020년 후반에 검색 기능 향상, metadata 수준 향상, 더 높은 해상도의 이미지 제공, 디지털 큐레이션 개선 및 옥스포드 내 대학들과 디지털 인문학 프로젝트를 위한 콘텐츠 전달 개선 등을 목적으로 재단장했다.
What 무엇을
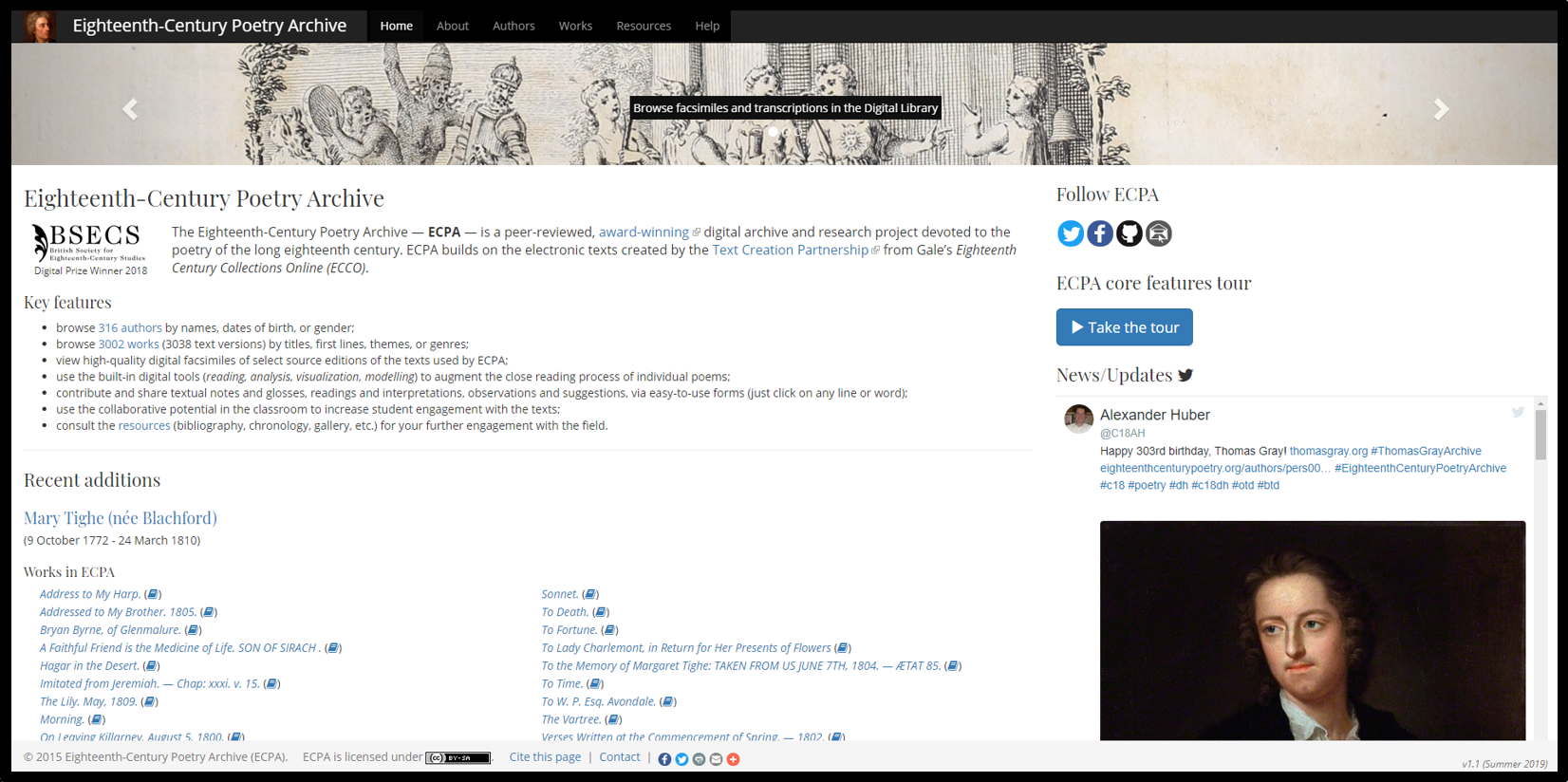
- 18세기 영국의 시와 시인들에 관한 다양한 1차, 2차 자료들 아카이브이다. 시 작품과 시인과 시에 대한 분석 및 정보 텍스트 자료부터 시인의 초상화와 같은 시각 자료들도 보유하고 있다.
- Eighteenth Century Poetry Archive는 ECCO-TCP에서 제공하는 디지털 텍스트를 기반으로 만들어졌다.
- Eighteenth Century Collections Online (ECCO) Text Creation Partnership (TCP)
- ECCO-TCP는 몇몇 대학 도서관들의 파트너십인 TCP가 교육 테크놀로지 회사인 Gale과 파트너십을 맺어서 만든 데이터베이스이다. 18세기 영국에서 출간된 영어와 외국어 자료들을 제공한다. 데이터베이스 내에는 3,200만 페이지의 텍스트와 205,000권의 책이 포함되어 있다. 해당 데이터베이스에서는 매우 정확하고, 검색 가능하며, SGML/XML 인코딩이 된 텍스트를 제공한다.
- Text Creation Partnership (TCP)는 University of Michigan Library, Bodleian Libraries at the University of Oxford, ProQuest, and the Council on Library and Information Resources가 1999년에 도서관의 혁신을 위해서 맺은 파트너십으로, 자료를 모으고, 텍스트를 검색하고 사용하기 유용하게 공동 기준에 맞게 만들며, 상업적으로 서비스를 제공하는 회사들과도 제휴한다. 현재까지 약 73,000개의 옛날 책들에 대한 디지털 컬렉션을 만들어서 제공하고 있다: ECCO-TCP, Early English Books Online–TCP, Evans Early American Imprints–TCP
How 어떻게
Search

- 상단 배너의 Search로 들어가면, 데이터 베이스 내의 모든 시의 목록을 볼 수 있다.
- 시의 제목, 작가, 주제, 장르, 내용 등으로 검색이 가능하다.
- 다양한 filter 존재: 시의 작가와 주제나 장르 뿐만 아니라 시의 세부적인 라임이나 형식인 rhyme patterns, rhyme positions, syllable patterns, stanza types, foot types, foot numbers, metrical patterns, metrical lines 에 따른 제한 검색도 가능하다.
Authors

- 작가들을 이름, 생년, 성별에 따라 보고, 검색할 수 있다.
- 왼편에는 Featured Author를 따로 소개한다.

- 작가 한 명의 페이지로 들어가보면, 그의 생애와 초상화, 그리고 Eighteenth-Century Poetry Archive에 있는 그의 작품들이 작품 페이지로 연결되는 링크와 함께 나열되어 있으며, 시들의 source edition도 나와있다. 게다가, 작가의 생애에 대한 설명(Biographical note)과 여러 참고문헌이 종류 별로 나와있다.
Works

- 작품들을 제목, 첫번째 줄/마지막 줄, 주제, 장르, 시의 출처가 되는 source edition에 따라 보고, 검색할 수 있다.
- 왼편에는 Featured Work를 따로 소개한다.
Reading

- 시 전문이 왼편에 나와 있고, 오른편에는 시에 대한 정보와, 시의 형식이 나와 있다. 그리고 해당 시의 출처(source edition)을 밝히고, 같은 작가의 다른 작품들과 그 작품으로 연결되는 링크가 나와 있다.
- 시 텍스트에 마우스를 대면, 그 시어에 대한 간단한 정보(품사, 복수형, 발음)이 나오고, 사용자가 그 시어에 대한 주석이나 질문을 추가할 수 있다.
Analysis





시의 각 행에 대해 언어학적 계층에 대한 분석으로, 음운론적(Phonological ), 형태론적(Morphological ), 구문론적(Syntactic ), 의미론적(Semantic), 문맥적(Pragmatic) 분석을 제공한다. 이와 같은 언어학적 분석은 컴퓨터 알고리즘을 기반으로 이루어질 수 있다. 각각의 언어학적 분석을 따로, 또 같이 연관 시켜서 보면서 시를 분석할 수 있다. 그리고 이러한 분석은 음운, 형태소와 같은 시의 작은 단위를 자세히 읽는 것부터 시작해서 결국 시 전체를 제대로 볼 수 있는 시각을 제공한다. 그리고 이러한 가까이 읽기와 역사적, 문화적 시각을 결합하면 결국 더 많은 시를 제대로 연구할 수 있게 될 것이다.
Visualization

- Phonemia: 시의 음소 구성을 시각화하는 도구로, 이 아카이브에서 개발되었다. 한 편의 시에서 어떤 음소가 어디에 얼마나 배치되어 있는지를 시각적으로 확인할 수 있다. 우선 자음과 모음 그룹으로 구분되고, 각각 자음과 모음 그룹 안에서 또 음소적 차이에 따라 분류가 되어 있다. 사용자는 특정 음소가 어디서 사용되었는지 색상 구분을 통해 알 수 있고, 각 행에서 몇 번 사용되었는지 표에 적힌 숫자를 통해 한 눈에 확인할 수 있다. 또한, 시에서 어떤 음소가 몇 번 사용되었는지, 가장 많이 사용된 음소가 무엇인지도 통계적으로 알 수 있다. 이러한 음소적 분석과 시각화는 시의 운율과 리듬을 파악하는 데에 도움이 된다.

- Poem Viewer: 시 전체에서, 혹은 시의 부분에서 소리의 움직임을 시각화 하는 도구로, University of Oxford와 the University of Utah의 협업으로 개발되었다. 이 도구는 시의 음소를 가로로 길게 제시하고, 각각의 음소들을 자음과 모음을 구분해서 음소적 단위, 음소적 특징, 음소적 관계를 생상과 도형, 선 등으로 시각화하여 상단에 표시한다. 또한 종합적인 시각을 위해 하단에는 음소들이 묶여서 단어를 이루는 형태와 반복되는 단어를 선으로 이은 것을 시각화하여 보여준다. 이러한 음소 시각화는 시의 부분과 전체를 유기적으로 살펴볼 수 있게 하기 위해서, 시각화 화면을 위 아래 두 가지로 제시한다. 아래에는 전체 시의 음소 시각화 분석을 간략하게 보여주고, 위에서는 선택한 부분 만을 더 자세하게 살펴볼 수 있다.

- DoubleTreeJS: 시의 문맥에서 한 단어의 다양한 쓰임을 한 눈에 시각적으로 볼 수 있게 해주는 도구이다. 어떤 단어를 검색하면, 시에서 그 단어를 기준으로 앞 뒤에 어떤 형태의 단어가 나왔는지를 가지처럼 시각화 한다. 이러한 가지를 속성별로 정렬하고 필터링할 수 있는 기능도 있다.
Kowledge Modeling

해당 시나 시인에 대해 다른 사용자가 미리 만들어 놓은 지식 모델링을 확인할 수 있다. 하나의 한 편의 시를 중심으로, 그 시의 작가 및 영향을 주고 받은 사람들, 그 시가 출판된 책, 장소, 시간 등 다양한 정보를 연결해 나가면서 큰 문맥을 살펴볼 수 있다. 이러한 지식 모델링은 디지털 문학 연구의 중요한 부분이며, 이전과는 다른 새로운 해석 프로세스의 출발점이 될 수 있다.
Resources
이 데이터베이스를 구축하면서 참고한 여러 참고문헌들 목록을 Bibliography에서 제시한다. 디지털 자료는 바로 하이퍼링크를 걸어놔서 바로 연결이 가능하다. 그리고 Chronology of Poetic Landmarks (1660-1800)에서는 1600년부터 1800년까지 년도별로 어떤 시인들이 태어나고, 또 죽었는지를 시대순으로 표기해놓았다. 마지막으로 Gallery of Author Portraits에서는 데이터베이스에서 제공하는 시인들의 초상화를 한번에 모아 놓고 볼 수 있게 해 놓았다.
Why 왜
Eighteenth Century Poetry Archive 설립의 주요 목적은 더욱 생생하고 협력적인 작업을 통해 18세기 시의 교육과 연구가 이루어지기 위함이다. 이러한 목적 달성을 위하여 18세기 시에 관한 높은 퀄리티의 1차, 2차 자료들을 가지고 있는 디지털 아카이브를 구축했다. 시 텍스트를 디지털로 이용할 수 있게 인코딩했고, XML 파일을 제공하며, 다양한 디지털 분석 및 시각화 도구를 제공한다. 또한, 많은 학자들과 학생들이 이 아카이브 내에서 협력할 수 있다. 사용자들은 각 텍스트에 주석이나 질문을 달 수 있고, XML 에디터를 통해 XML을 수정 및 개선할 수 있으며, 본인이 만든 지식 모델링을 공유할 수 있다. 이러한 통합 아카이브를 통해서 18세기 시 연구에 학술적인 공헌을 할 수 있기를 기대한다.
Comment 논평
18세기 시 아카이브는, 해당 아카이브가 코퍼스 자료를 가져온 ECCO-TCP 데이터 베이스와 비교하면, UI/UX가 훨씬 편리하게 잘 구축되어 있다. 시인 별로, 시대 별로, 심지어는 주제와 장르 별로 시를 분류한 것은 자료를 접근하는 데에 훨씬 편리하게 느껴졌다. 그리고 단순히 시와 시인 만을 제시하는 것이 아니라, 믿음직한 참고문헌들에서 추가적인 정보를 추가해서 이를 공부하는 학생들에게 도움이 될 것으로 보인다. 그리고 여러 디지털 시각화 자료들을 사용한 점도 흥미로웠다. 단순한 언어학적 분석부터, 외부의 도구를 사용한 시각화까지 제공해서, 시의 텍스트만 보는 것을 넘어서서, 디지털이라는 장점을 활용해서 시에 대한 더 넓은 시각의 다양한 경험을 제공한 것은 특기할만 하다. 전반적으로 시라는 문학 작품을 다양한 디지털 도구를 사용해서 고차원적인 데이터 베이스를 만들어 낸 것으로 보인다.
하지만 아쉬운 점이 몇 가지 있다. 우선, 근원적으로 왜 18세기 시를 주제로 아카이브를 만들었는지에 대한 설명이 부족하다. 이 아카이브의 관리자의 전공과 관심사가 18세기 시이기 때문에 이 프로젝트를 진행한 것이다. 물론 영미시사에서 18세기가 신고전주의에서 낭만주의로 넘어가며 주요 시인들을 많이 배출한 중요한 시기이기는 하지만, 그에 관한 추가적인 설명이 있었다면, 꼭 18세기를 연구하는 학자들 뿐만 아니라 다른 시대나 종류의 문학에 관심이 있는 더 많은 사람들도 이 아카이브의 필요성과 중요성을 인식할 수 있을 것 같다는 생각이 들었다. 아마 이 프로젝트의 확장으로 18, 19세기가 중심이 되는 낭만주의 시 아카이브인 Romantic-Period Poetry Archive를 현재 구축하고 있으며, 이 프로젝트에는 전 세계의 시와 시인을 포함해서 지도 상에 나타내는 작업도 진행하고 있다.
또한, 결국 시에 대한 분석이 디지털 도구를 활용한 언어학적 분석에서 그치는 것이 아쉬웠다. 이 데이터 베이스가 그래도 일반 아카이브보다 발전한 부분은 다양한 분석과 시각화 도구를 제공한다는 것이다. 그러나, 각 한 편 한 편을 언어학적인 분석 알고리즘에 넣는 것에 그치는 것이 아쉬웠다. 만약 기본 시 텍스트 데이터를 태깅 작업을 하는 식으로 좀 더 가공하거나, 아카이브에 구축된 전체 시에 관한 간단한 코퍼스 분석이라도 이루어졌거나, 이루어질 수 있는 환경이라면 더 풍부한 학술적 공간이 되었을 것이라고 생각한다. 이 아카이브에서 시의 형식에 대한 가까이 읽기는 가능하지만, 시의 의미를 파악하기에는 부족하다고 느꼈다. 지식 모델링을 제공하기는 하지만, 아직까지 이 아카이브의 관리자가 업로드한 모델만 적게 존재하는 점(필자는 Thomas Gray의 Imitation에 대한 지식 그래프 하나만 발견했다)도 아쉽다.
(류인태 교수님 논평 추가) 하지만 이런 언어학적 분석은 현재 연구자들 사이에서 활발하게 이루어지지 않고 있기 때문에, 해당 아카이브에서 이를 제공한다는 의의가 있다. 문학 연구에서는 시의 맥락과 의미 등을 파악하는 연구를 주로 하고, 언어학자들은 언어학적 관점에서의 문학 연구를 통해 문학적 관점에 맞는 결과를 낼 수 없으므로 잘 시도하지 않는다. 그래서 이러한 연구적 공백을 이 아카이브에서 다양한 디지털 방법을 활용해서 메꿨다고 볼 수도 있다. 또한, 이러한 언어학적 분석을 이미 기존에 있었던 자료와 도구들을 사용해서 실행했다는 점도 주목할 만하다. 이는 디지털 인문학 연구에서 기초 자원의 중요성을 보여주는 사례이다. 또한, 지식 모델링 설계는 설계하는 과정에서 데이터를 선택하고, 구축하며 연구자의 주관적인 입장이 들어갈 수도 있기 때문에 객관화, 보편화 하기는 어려운 자료라는 지적을 받는다. 그러므로, 해당 아카이브에서는 관리자가 직접 지식 그래프를 설계해서 제공하는 것이 아니라, 관리자는 샘플 정도만 제공하고, 사용자들이 자유롭게 각자의 관점에 맞게 지식 모델링을 구현하고 이를 공유할 수 있도록 해놓았다. 이는 시에 대한 객관적인 분석과 각 사용자가 보는 시에 대한 주관적인 관점을 해치지 않고, 사용자들이 자유롭게 지식 그래프 구현에 참여해서 이를 공유하고 의견을 나누는 협업의 장을 만든다는 데에도 큰 의의가 있다.- ↑ ECPA 사이트에는 Alexander Huber 만 해당 프로젝트의 founder이라고 명시되어 있다. 하지만, 옥스포드 대학의 해당 프로젝트 소개에서는 Alexander Huber와 Emma Huber가 함께 작업을 했다고 표기되어 있다.
- ↑ 18세기 연구 분야의 디지털 자료들을 한 곳에서 검색할 수 있는 웹사이트. 18세기에 관한 것을 검색하면 그에 대한 학술적인 자료가 있는 웹사이트의 링크를 제공한다.
- ↑ Poetry Standardization and Linked Open Data. 시를 machine-readable한 데이터로 만들어서, 디지털 인문학 연구 환경에서 시를 연구할 수 있도록 만들기 위한 프로젝트. 2015년-202년에 European Research Council (ERC)의 펀드를 받아서 진행되었다.
- ↑ ECPA 프로젝트는 Alexander Huber 개인이 주도해서 진행한 작업으로 보인다. 하지만, 그가 작업 당시 Oxford University의 Bodleian Library 소속이었고, Oxford University의 Text Creation Partnership와 Oxford Text Archive의 디지털 텍스트 자료를 사용했으며, Digital Humanities @ Oxford에서 해당 프로젝트를 소개하고 있는 것 등을 고려해봤을 때, 해당 위키에서 "Where/어디서"는 Oxford University의 Bodleian Library로 상정한다.