"Busan Data Guide"의 두 판 사이의 차이
| 491번째 줄: | 491번째 줄: | ||
<li><strong> <a href="https://busandabom.net/index.nm?menuCd=105">『부산의 자연마을』전 6권</a> </strong> </li> | <li><strong> <a href="https://busandabom.net/index.nm?menuCd=105">『부산의 자연마을』전 6권</a> </strong> </li> | ||
<li><strong> <a href="https://busandabom.net/index.nm?menuCd=110">『부산을 빛낸 인물』전 3권</a> </strong> </li> | <li><strong> <a href="https://busandabom.net/index.nm?menuCd=110">『부산을 빛낸 인물』전 3권</a> </strong> </li> | ||
| − | <li><strong> <a href="https://docs.google.com/document/d/1I-bov6PDifJkqLkjBKopsXauVQU5NWSySAi_VA1BxG4/edit?usp=sharing">보조연구원 활동일지</a> </strong> </li> | + | <li><strong> <a href="https://script.google.com/macros/s/AKfycbxWAfQ8l8_BEurbtQq8hAFS76zWnxnj8O3nNjEFo_rGdDkWMQcjkmaCVas5eREZxTV1/exec" target="_blank">오리엔테이션 출석체크</a></strong> </li> |
| + | <li><strong> <a href="https://docs.google.com/document/d/1I-bov6PDifJkqLkjBKopsXauVQU5NWSySAi_VA1BxG4/edit?usp=sharing">보조연구원 활동일지 서식 보기(개별 배포 예정)</a> </strong> </li> | ||
</ul> | </ul> | ||
</div> | </div> | ||
2026년 1월 3일 (토) 21:40 판
📚 부산 지역 인문학 자료 디지털화(Digitalization) 가이드
『부산을 빛낸 인물』과 『부산의 자연마을』의 디지털 데이터 변환
📖 들어가며
본 프로젝트는 부산광역시 문화유산과 시사편찬실에서 발간한 『부산을 빛낸 인물』과 『부산의 자연마을』이라는 부산의 인문 자료를 디지털 데이터로 변환하는 기초 작업입니다.
📚 프로젝트 규모 및 팀 구성
작업 대상 자료: 부산광역시사편찬위원회 자료실 또는 부산 지역사 도서관에서 PDF 다운로드 & 모든 팀원 활동일지 다운로드
👥 역할 분담 (총 26명: 인문계 23명 + 이공계 3명)
역할: 인문계 학생들은 텍스트 구조화(EXCEL) 및 태깅(XML) + 이공계 학생들은 기술 지원 및 자동화
『부산을 빛낸 인물』전 3권 (780 페이지)
- 구조화: 황인영, 이선영 (390페이지씩)
- 태깅: 박하영, 김남희, 최은
- 검수: 박수연
『부산의 자연마을』제1, 2, 6권(1,140여 페이지)
- 구조화: 김수민, 김주난, 임승주 (380페이지씩)
- 태깅: 김수인, 김민경, 홍정빈
- 검수: 정재환
『부산의 자연마을』제3, 4, 5권(1,140여 페이지)
- 구조화: 김수영, 엄미연, 윤채영 (380페이지씩)
- 태깅: 우지성, 임혜민, 조혜원
- 검수: 노수미
전체 작업 (약 3,000 페이지)
- 원본 파일(txt): 이다원, 최나영 (1500페이지씩)
- 이미지 및 전체 검수: 윤수현
- 전처리 및 XML 변환: 강주연, 박지현, 박비원
- 구조화: PDF에서 추출한 텍스트를 팀별 작업 시트에 입력
- 매주 일정 분량씩 검수자에게 제출
- 태깅: 의미 요소 식별 (XML 태깅을 위한 준비 작업)
- 검수: 누락된 부분 없는지 확인 및 작업 일정 관리
- 파이썬 스크립트 개발 (태깅 마커 [P][/P] → XML 자동 변환)
- 데이터 검증 및 오류 체크 자동화
- 팀 내 기술적 문제 실시간 지원
- VScode, Git 등 도구 활용 지원
이제 책 속의 자료를 시맨틱 데이터로 변환하는 기초 작업을 진행할 예정입니다. 왜 이 작업이 필요할까요?
부산광역시사편찬위원회 자료실에 PDF로 제공되는 도서는 한 번에 한 사람만 읽을 수 있지만, 디지털 데이터로 변환된 지식은:
- 💡 검색 가능: "1950년대 부산 영도구"라고 검색하면 관련된 모든 내용이 한눈에 보이게 만들 수 있습니다!
- 🔗 연결 가능: 인물과 장소, 사건이 서로 연결되어 새로운 통찰을 발견할 수 있습니다!
- 📊 분석 가능: 빈도, 패턴, 관계를 통해 보이지 않던 역사적 의미를 발견할 수 있습니다!
- 🌐 공유 가능: 전 세계 연구자들과 부산의 이야기를 나눌 수 있어요
🔥 전체 로드맵: 3단계 여정
디지털화(Digitalization) 기초 작업
현재 단계
- PDF → 텍스트 추출
- 구조화 → CSV 정리
- 태깅 → XML 변환
목표: 원천 자료를 DB에 업로드 가능한 형태로 구조화
데이터 분석(Data Analysis)
- 빈도 분석 & 키워드 추출
- 관계 파악
- 의미 해석
목표: 구축된 데이터에서 학문적 의미와 패턴 도출
데이터 설계(Data Modeling)
- 온톨로지 설계
- 지식 그래프 구상
- 활용 방안 기획
목표: 플랫폼 구축을 위한 데이터 모델링
📊 작업 일정 계획 (2026년 1월~2월)
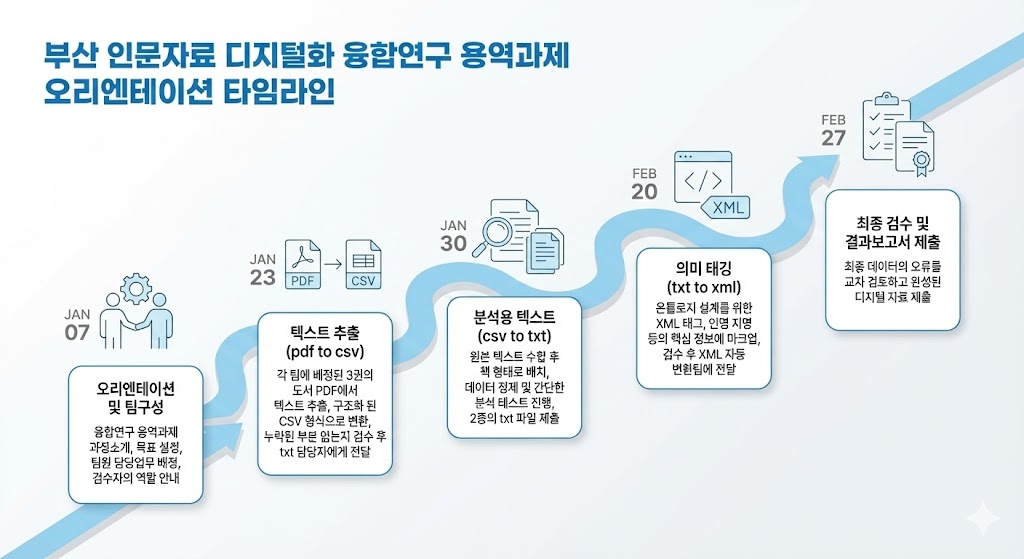
부산 인문자료 디지털화 온보딩 타임라인
- 『부산을 빛낸 인물』: 총 783페이지(A팀)
- 『부산의 자연마을』: 총 2,272페이지
- B팀: 1,141페이지
- C팀: 1,131페이지
※ 각 팀은 작업량을 할당하여 2개월간 데이터 정리 작업을 진행하고 기록합니다.
| 기간 | 목표 | 세부 과제 |
|---|---|---|
| 1월 23일 | csv 작업 파일 및 txt 원본 제출 |
|
| 1월 30일 | txt 전처리 파일 및 기본 구조화 작업 파일 제출 |
|
| 2월 20일 | XML 마커 샘플 작업파일 제출 |
|
| 2월 27일 | 완료 및 품질 검수 + XML 변환 |
|
📊 우리 팀 데이터 구조 이해하기
우리가 사용하는 구글 시트는 18개의 필드(열)로 구성되어 있어요. 각 필드가 왜 필요한지 함께 살펴볼까요?
🔑 핵심 필드 설명
| 필드명 | 예시 | 설명 | 작업자가 할 일 |
|---|---|---|---|
id |
txt_10001 | 단락별 정보를 하나로 묶는 고유 번호 | 필수 반드시 부여 (중복 금지!) |
book_id |
lightuppeople01 | 책 식별자(부산지역사도서관 PDF 파일명을 따름) | 책마다 고정값 사용 |
book_title |
부산을_빛낸_인물 | 책 제목 | 언더바(_)로 연결 |
sub_title |
20세기_이전_인물편 | 부제목 | 있는 경우만 입력 |
publisher |
부산광역시_문화유산과_시사편찬실 | 발행처 | 책 정보 그대로 |
pub_date |
2004.06 | 출판일 | YYYY.MM 형식 |
chapter |
001 | 장 번호 | 3자리 숫자 (001, 002...) |
page |
005 | 페이지 | 3자리 숫자 (005, 006...) |
person_id |
per_10001 | 인물 고유 번호 | 필수 새 인물마다 부여 |
name_ko |
최치원 | 인물 한글 이름 | 정확하게 입력 |
name_ch |
崔致遠 | 인물 한자 이름 | 있는 경우만 입력 |
topic |
해운대의_유래 | 소주제 | 섹션 제목 그대로 |
author |
정경주_경성대교수 | 글쓴이 | 이름_소속 형식 |
text_original |
(본문 내용) | 원문 텍스트 | 필수 가장 중요! |
text_type |
normal/citation | 텍스트 유형 구분 | 추후 인용문만 별도로 추출 가능 |
relation_note |
txt_10008 | 관련 텍스트 ID | 단락이 연결되는 경우에만 기입 |
img_caption |
최치원_영정 | 이미지 설명 | 이미지 있을 때만 |
remark |
번역문 / 원문 | 자유롭게 여러 가지 정보를 기술, 언더바 불필요 | 필수 2월말에 결과보고서로 제출 |
📖 실전 예시로 배우기
사례 1: 일반 텍스트 처리하기
PDF 원문 (5페이지)
스프레드시트 입력 결과
| id | book_title | chapter | page | person_id | name_ko | topic | text_type |
|---|---|---|---|---|---|---|---|
| txt_10001 | 부산을_빛낸_인물 | 001 | 005 | per_10001 | 최치원 | 해운대의_유래 | normal |
- ✅ id는 연속된 번호: txt_10001, txt_10002, txt_10003...
- ✅ person_id는 새 인물 등장시에만 변경
- ✅ 한 문단 = 한 행: 문단 단위로 나누어 입력
- ✅ text_type은 'normal': 일반 서술 텍스트
사례 2: 인용문(citation) 처리하기
PDF 원문 (6페이지)
스프레드시트 입력 결과
| id | text_original | text_type | relation_note |
|---|---|---|---|
| txt_10006 | 최치원은 857년(헌안왕 원년)에 신라의 서울 경주에서 태어났다 | normal | |
| txt_10007 | 제 나이 열 두살 때 집을 떠나 서쪽으로 갔습니다.(도서 원본에서는 볼드체로 표시) | citation | txt_10006 |
- ✅ text_type을 'citation'으로: 직접 인용문임을 표시
- ✅ relation_note 활용: 앞 문장(txt_10006)과 연결됨을 표시
- ✅ 따옴표 포함: 원문의 인용 부호 그대로 유지
사례 3: 운문(verse) 처리하기 - 가장 까다로운 부분!
PDF 원문 (11페이지) - 정서의 시
스프레드시트 입력 결과 - 원문과 번역문을 분리!
| id | person_id | name_ko | text_original | text_type | relation_note | remark |
|---|---|---|---|---|---|---|
| txt_10013 | per_101_002 | 정서 | 狂奔疊石吼重巒 / 人語難分咫尺間 / 常恐是非聲到耳 / 故敎流水盡籠山 | poem | txt_10014 | 원문 |
| txt_10014 | per_101_002 | 정서 | 미친 물 바위 치며 겹겹 산을 뒤흔드니 / 지척 사이에도 사람 소리 모르겠네. / 세상의 시비 소리 들릴까 두려워서 / 짐짓 흐르는 물로 산을 온통 가두었네. | poem | txt_10013 | 번역문 |
- ✅ 한문 원문과 번역문 = 2개 열: 별도로 입력 후 relation_note로 연결!
- ✅ remark에 명시: '원문' 또는 '번역문'
- ✅ relation_note로 연결: XML에서 [corresp id="txt_10013"]으로 대응시킴으로써 특정 원문에 대한 번역문임을 명시
- ✅ 연(구절) 구분은 슬래시(/): 狂奔疊石吼重巒 / 人語難分咫尺間 --> XML에서 [lg] [l]狂奔疊石吼重巒[/l] [/lg](ling group) 으로 변환
사례 4: 가사(歌辭) 처리하기
PDF 원문 (19페이지) - <삼진작 三眞勺>
- ✅ 운문으로 처리: 현대시, 한시, 가사 모두 운문(verse)으로 분류
- ✅ remark에 작품명: 인용문의 출처나 제목을 알 수 있다면 remark에 기입
- ✅ 특수문자 처리: 처럼 깨진 부분은 원문 그대로 표시
🔢 ID 부여 규칙 마스터하기
1. 텍스트 ID (id) 규칙
- 형식:
txt_+ 5자리 숫자 - 시작: 10001부터 시작
- 연속성: 중간에 번호를 건너뛰지 않음
- 고유성: 전체 데이터베이스에서 중복되면 안 됨!
2. 인물 ID (person_id) 규칙
- 형식:
per_+ 5자리 숫자 - 책번호:
- 10001 = 『부산을 빛낸 인물』 권1
- 20001 = 『부산을 빛낸 인물』 권2
- 40001 = 『부산의 자연마을』 권1
- 인물번호: 첫자리수는 권마다 달라지며 등장 순서대로 부여
실전 예시
| 상황 | person_id | 설명 |
|---|---|---|
| 최치원이 5페이지에서 처음 등장 | per_10001 |
첫 번째 인물 |
| 정서가 11페이지에서 처음 등장 | per_10002 |
두 번째 인물 |
| 최치원이 다시 15페이지에 등장 | per_10001 |
동일 ID 재사용! |
- 인물 등장 순서대로 번호 부여: 페이지 순서가 아니라 등장 순서
- 같은 인물은 같은 ID: 다른 책에 등장해도 같은 인물이라면 ID는 하나
- 엑셀 필터 활용: 이미 부여된 인물 ID 확인하기
💻 실습용 작업 스프레드시트
아래는 우리 팀이 실제로 작업하는 구글 시트입니다. 실시간으로 데이터를 확인하고 입력할 수 있어요.
- 위 임베드 창에서 바로 데이터를 확인할 수 있어요
- 실제 입력은 "새 탭에서 열기" 버튼을 클릭해서 진행하세요
- 여러 사람이 동시에 작업할 수 있어요 (실시간 공동 편집)
- 변경 이력은 자동으로 저장됩니다
✅ 최종 체크리스트
작업 완료 전에 꼭 확인하세요!
- id가 연속되어 있나요? (txt_10001 → txt_10002 → txt_10003)
- person_id가 올바르게 부여되었나요?
- 같은 인물이 여러 곳에 나오면 같은 person_id를 사용했나요?
- text_type이 정확한가요? (normal/citation)
- 시의 원문과 번역문을 분리했나요?
- relation_note로 관련 텍스트를 연결했나요?
🏷️ XML 태깅: 데이터에 의미 부여하기
CSV로 정리한 텍스트에 의미론적 태그(Semantic Tags)를 붙여서 컴퓨터가 "누가", "어디서", "언제" 같은 정보를 이해할 수 있게 만드는 작업입니다.
🎯 왜 XML 태깅이 필요한가요?
최치원은 857년에 경주에서 태어났다.
→ 컴퓨터는 그냥 글자로만 인식
<persName>최치원</persName>은
<date when="857">857년</date>에
<placeName>경주</placeName>에서 태어났다.
→ 인물, 시간, 장소를 구분해서 인식!
📚 온톨로지 설계 참고: 광주인문도시 사례
우리 프로젝트는 광주인문도시스토리플랫폼의 온톨로지 설계를 참고합니다:
광주 사례에서는 Agent(인물), Event(사건), Place(장소), Architecture(건축물) 등의 클래스를 정의했습니다. 우리는 이를 선행모델로 참고해서 같은 방식으로 부산 데이터를 설계하고, 웹상에 개방하여(Open) 웹 표준(URI)을 통해 광주 데이터와 연결(Linked)할 것입니다. 만약 우리가 우리 마음대로 이름을 붙여서 데이터를 만들면, 광주 데이터와 부산 데이터는 서로 다른 언어를 쓰는 셈이라 섞일 수가 없습니다. 하지만 우리가 같은 규칙(Class)을 쓰면, 컴퓨터는 부산의 플랫폼에 업로드 될 '최치원'과 광주의 플랫폼에서 언급하는 '최치원'이 같은 '인물(Actor)'이라는 것을 이해하고 서로 연결할 수 있게 됩니다. 이렇게 누구나 쓸 수 있도록 공개된 데이터(Open Data)들이 서로 표준화된 방식으로 연결(Linked)되어, 마치 거미줄처럼 정보를 확장해 나가는 것을 'LOD(Linked Open Data)'라고 합니다. 우리는 부산의 데이터를 만들어 거대한 지식의 웹(Web)에 연결하는 작업을 하는 것입니다.
앞으로 우리가 하게 될 XML 태깅은 컴퓨터에게 '이 단어는 그냥 글자가 아니라, 사람 이름이야'라고 알려주는 인식표를 달아주는 작업입니다. 우리가
🎯 단계별 태깅 전략 (난이도별 접근)
1차 작업 (필수) - 가장 명확한 요소
현재 작업 단계
| 인명 | [P]최치원[/P] |
사람 이름 (판단 쉬움) |
| 지명 | [L]영도구[/L] |
장소, 지역명 (판단 쉬움) |
💡 추천: 학부생 기초 작업은 인명과 지명만 집중하는 것을 권장합니다!
- ✅ 판단이 가장 명확
- ✅ 작업 속도가 빠름
- ✅ 온톨로지 핵심인 "누가-어디서" 관계망 우선 구축
2차 작업 (선택) - 조금 더 복잡
| 시간 | [D]1876년[/D] |
날짜, 연도, 시대 |
| 기관명 | [O]동래부[/O] |
단체, 조직, 관청 |
| 서명 | [T]동래부지[/T] |
책, 문서, 작품명 |
진행 시기: 1차 작업 완료 후 또는 동시 진행 가능
3차 작업 (고급) - 전문가 검수 필요
| 문화유산 | [H]동래읍성[/H] |
유적, 문화재, 건축물 |
| 사건명 | [E]임진왜란[/E] |
역사적 사건, 행사 |
| 작품명 | [W]해운대가[/W] |
시, 그림, 예술작품 |
진행 시기: 데이터 분석 및 설계 단계에서
※ 문화유산과 지명, 작품명과 서명의 구분이 애매할 수 있어 전문가 판단 필요
🔍 1차 작업: 인명 + 지명 태깅 실전
예시 1: 『부산을 빛낸 인물』
원문:- 인명: 사람 이름 (최치원, 헌안왕, 경문왕)
- 지명: 장소/지역 (신라, 경주, 당나라)
- 제외: 857년, 868년 같은 시간 표현 (2차 작업에서!)
예시 2: 『부산의 자연마을』
원문:- 지명: 영도구, 동삼동, 절영도, 부산부 (모두 장소)
- 인명: 없음
- 제외: 조선시대, 1876년, 1942년 (2차 작업에서!)
🔄 작업 도구별 역할 정리
| 단계 | 도구 | 작업 내용 | 담당 |
|---|---|---|---|
| 1단계 csv | Excel / Google Sheets | CSV 데이터 입력 (text_original) | 전체 팀원 |
| 2단계 txt | Notepad++ / VSCode | 태깅 마커 표시 (text_tagged) | 인문계 학생 |
| 3단계 xml | Python | 마커 → XML 자동 변환 | 이공계 학생 |
| 4단계 valid check | XML Validation 도구 | XML 파일 검수 및 수정 | 팀 총괄 + 전체 |
- 일관성 유지: 같은 대상은 항상 같은 방식으로 태깅
- 중첩 금지: [P][L]김해[/L][/P] (X) → 하나만 선택
- 불확실하면 표시 안 함: 확실한 것만 태깅
- Excel에서 작업: 익숙한 도구로 빠르게 진행
- VSCode는 검수용: XML 변환 후 최종 확인에만 사용
📊 태깅 진도 체크리스트
- 인명과 지명의 차이를 구분할 수 있나요?
- 마커 표기법([P], [L])을 이해했나요?
- Excel에 text_tagged 열을 추가했나요?
- 샘플 10개 문단을 태깅해보았나요?
- 팀원들과 태깅 기준을 통일했나요?
- VSCode를 설치하고 XML Tools 확장을 설치했나요?
💬 자주 묻는 질문 (Q&A)
Q1. 인물이 명확하지 않은 경우는?
A. person_id를 비워두고, remark에 "인물 미상" 표시
Q2. 여러 인물이 한 문단에 나오면?
A. 주요 인물의 person_id를 사용하고, remark에 "김철수, 이영희 등장" 메모
Q3. 페이지 번호가 불분명하면?
A. 앞뒤 맥락으로 유추하고, remark에 "페이지 추정" 표시
Q4. 작업 중 막힐 때는?
A.
- 팀 단톡방에 질문
- 매주 팀별로 정기 모임(zoom)
- 작업 메뉴얼 재확인
🎯 마무리
기억해야 할 핵심 3가지
- 일관성이 생명: 같은 항목은 항상 같은 방식으로
- ID는 신중하게: 한번 부여한 ID는 앞으로도 계속 사용될 예정
- 협업이 중요: 막힐 때는 팀원들과 의논하기(논의가 필요하다 생각한 부분을 결과보고서에 기입!!)
📎 참고 자료
- 작업 스프레드시트: 구글 시트 바로가기
- XML 가이드: XML 설계 입문
- 광주인문도시스토리플랫폼: 사례 참고