온톨로지 설계 방법
DH 교육용 위키
목차
온톨로지(Ontolgy)란?
- ‘온톨로지’란 정보화의 대상이 되는 세계를 전자적으로 표현할 수 있도록 구성한 데이터 기술 체계이다.
- 정보기술 분야에서 말하는 ‘온톨로지(ontology)’에 대한 가장 일반적인 정의는 그루버(Gruber, Thomas. 1959~ )가 말한 ‘명시적 명세화의 방법에 의한 개념화’(explicit specification of a conceptualization)이다.[1]
- ‘개념화’(conceptualization): 정보화하고자 하는 대상 세계를 일정한 체계 속에서 파악하는 것, 예를 들면 그 세계에 무엇이 있고, 그것은 어떤 속성을 품고 있으며, 그것들 사이의 관계는 무엇인가 하는 일정한 질문의 틀 속에서 대상 세계를 이해하는 방식.
- ‘명세화’(specification): 대상 세계에 존재하는 개체, 속성, 관계 등을 일목요연한 목록으로 정리하는 것.
- ‘명시적’(explicit): 그 정리된 목록을 사람뿐 아니라 ‘컴퓨터가 읽을 수 있도록’(machine readable) 한다는 것.
- 원래 온톨로지라는 말은 철학에서 ‘존재론’이라고 번역되는 용어로서 ‘존재에 대한 이해를 추구하는 학문’의 의미를 갖는 말이었다. 그러한 용어가 정보과학 분야에서 중요한 개념으로 등장하게 된 것은 인간이 세계를 이해하는 틀과 컴퓨터가 정보화 대상(콘텐츠)을 이해하는 틀 사이에 유사성이 있다고 보았기 때문이다. 그 틀은 바로 대상을 구성하는 요소들에 대응하는 개념들과 그 개념들 간의 연관 관계이다.[2]
* 넓은 의미에서는 모든 정보화의 틀이 다 온톨로지일 수 있겠지만, 대상 자원을 ‘클래스’(class)로 범주화하고, 각각의 클래스에 속하는 개체(individuals)들이 공통의 ‘속성’(attribute)을 갖도록 하고, 그 개체들이 다른 개체들과 맺는 ‘관계’(relation)를 명시적으로 기술하는 것이 가장 일반적인 온톨로지 설계 방법이라고 할 수 있다. ==온톨로지 설계==
- 정보화 대상 예시: 담양 소쇄원
 
|
===⓵ 개체(individual) 탐색===
온톨로지 설계를 위해 제일 먼저 할 일은 정보화 하고자 하는 지식 세계에 어떠한 지식 요소들이 있는지 탐색하고, 그 성격을 분석하는 것이다. 위의 예시에서 목록화한 개개의 요소들을 온톨로지 용어로는 ‘개체’라고 한다. 이것은 정보화하고자 하는 지식의 단위 요소이자, 관련 지식의 네트워크에서 관계의 접점이 될 노드(node)이다.
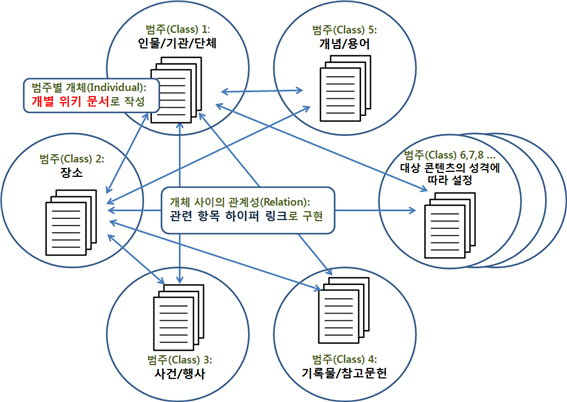

⓶ 클래스(class) 설계
정보화의 대상 세계에 대체로 어떠한 성격의 문맥 요소가 존재하는지 파악되었으면, 그 다음에 할 일은 그 요소들 가운데 서로 유사한 성격의 것들을 묶어줄 수 있는 범주를 정하는 것이다. 온톨로지 용어로는 이러한 범주를 클래스라고 한다. 이 클래스 설계는 대상 세계를 무차별적인 사실/사물의 나열로 보지 않고, 일정한 체계 속에서 이해하려는 노력이라고 할 수 있다. 따라서 어떠한 클래스를 정하느냐 하는 것은 연구자가 대상을 어떠한 시각에서 보고자 하느냐에 따라 달라진다. 파일:OntologyDesign2.jpg
{kind=link}
⓷ 속성(attribute) 설계
클래스 설계가 이루어졌으면, 각각의 클래스에 속하는 개체(individual)들이 어떤 속성을 갖는지를 살피고, 이 속성을 담을 수 있는 틀을 만들어야 한다. 예를 들어 ‘인물’ 클래스에 속하는 개체들에 대해서는 이름, 이름의 한자 표기, 별명(자, 호, 봉작호, 시호 등), 생몰년, 관직 등의 정보를 부여하는 것이다. 클래스 설계와 마찬가지로 속성 설계도 ‘이렇게 해야 한다’는 절대적인 기준은 없다. 대상 개체를 어떤 관점에서 보고 있으며, 그 정보를 어떠한 목적으로 사용할 것인가를 기준으로 삼으면 된다. 파일:OntologyDesign3.jpg
{kind=link}
⓸ 관계성(relation) 설계
각각의 클래스에 속하는 개체들이 서로 어떠한 의미적 연관 관계를 맺고 있는지 분석하여, 그 관계성을 표현할 수 있는 서술어를 정한다. 이 관계성 서술어는 주어와 목적어를 수반하여 RDF(Resource Description Framework) 문을 완성하게 된다. 이 때 주어 역할을 할 수 있는 개체들의 클래스를 ‘정의역’(定義域, domain)이라고 하고, 목적어 역할을 하는 개체들의 클래스를 ‘치역’(値域, range)라고 부른다. 파일:OntologyDesign4.jpg
{kind=link}
⓹ 개체(individual)에 대한 속성, 관계성 부여
지금까지 수행한 네 가지 과정이 온톨로지 설계에 해당하는 일이라고 한다면 이 다섯 번째 작업은 설계된 온톨로지에 따라 데이터베이스를 구축하는 일이다. 온톨로지 설계에 의해 만들어진 데이터베이스를 일반적인 관계형 데이터베이스(Relational Database, RDB)와 구분하여 ‘온톨로지 기반 데이터베이스’(Ontology Based Database, ODB)라고 부르기도 한다. 파일:OntologyDesign5.jpg
{kind=link}
==시맨틱 데이터베이스의 구현==
문맥 요소로 발굴된 모든 개체를 해당 클래스에 귀속시킨 후, 각각의 개체에 고유한 속성을 부여하고, 개체와 개체 사이의 관계성을 지정하는 방법으로 온톨로지 기반 데이터베이스를 구현하면, 그 속에 담긴 개체들이 관계의 맥락을 명시적으로 드러내게 된다. 이와 같이 개체에 대한 개별적 정보뿐 아니라 그것들 사이의 의미적 연관관례를 담고 있는 데이터베이스를 ‘시맨틱 데이터베이스’(Semanti Database)라고 한다. 파일:OntologyDesign6.jpg
{kind=link}
==시맨틱 데이터베이스의 확장== 이 데이터는 이것의 원시 데이터라고 할 수 있는 안내판 해설문 속의 정보를 컴퓨터가 읽고 해석할 수 있는 형태로 가공한 것이라고 할 수 있다. 이와 같은 기계가독형(Machine-Readable) 데이터를 만들어서 얻는 이점은 무엇일까? ‘담양 소쇄원’이라는 하나의 문화유산 정보만 디지털화한 상황에서는 온톨로지 기반 데이터베이스의 장점을 드러내기 힘들다. 하지만 이러한 정보가 수천 건, 수만 건 있다고 가정해 보면, 다음과 같은 효과를 쉽게 기대할 수 있다. 여러 가지 기대 효과 가운데 가장 우선시되는 것은 별개의 문화유산 해설문 속에 담겨 있는 정보들이 서로서로 관련성을 좋아 광대한 의미의 연결망을 만들 수 있을 것이라는 점이다. ‘용인 심곡서원’에는 양산보의 스승 조광조가 제향되어 있다. ‘장성 필암서원’에 제향된 김인후는 양산보의 친구이고, 김인후와 함께 제향된 그의 제자 양자징은 양산보의 아들이다. 이 세 곳의 문화유산들은 공통의 관련 인물을 매개로 다음 그림과 같은 관계망을 형성한다. 파일:OntologyDesign7.jpg 이와 같이 서로서로 의미의 연결고리를 맺고 있는 지식의 네트워크 속에서는 그 관계를 추론하여 새로운 지식을 얻는 것도 가능하다. 우리가 이 예시를 위해 만든 데이터 안에서도 ‘소쇄원을 만든 사람의 스승은 누구인가?’, ‘그를 제향한 서원은 어디인가?’라는 질문을 던지면, 컴퓨터는 그 질문에 대해 정확한 답변을 제공한다. 이 온톨로지를 공유하는 더 많은 데이터가 만들어졌을 경우, 컴퓨터는 보다 유용한 지식 탐구의 동반자 역할을 할 수 있을 것이다.
{kind=link}
{kind=link}
----
- ↑ Gruber, ‘A Translation Approach to Portable Ontology Specifications’, Knowledge Systems Laboratory Technical Report KSL 92-71, Stanford University, 1992.
- ↑ 김현, 「한국 고전적 전산화의 발전 방향 - 고전 문집 지식 정보 시스템 개발 전략 -」, 『민족문화』 28 (2005)
※ 이 기사는 『디지털 인문학 입문』(김현 외, HUEBOOKs, 2016, 5. 31.) 제2편 Ⅳ-3. 온톨로지의 글을 발췌. 정리한 것입니다.